
매달, 우리는 1000명 이상의 사람들이 시험 준비를 잘하고 시험을 잘 통과할 수 있도록 도와줍니다.
UiPath Certified Professional Specialized AI Professional v1.0 온라인 연습
최종 업데이트 시간: 2025년11월17일
당신은 온라인 연습 문제를 통해 UiPath UiPath-SAIv1 시험지식에 대해 자신이 어떻게 알고 있는지 파악한 후 시험 참가 신청 여부를 결정할 수 있다.
시험을 100% 합격하고 시험 준비 시간을 35% 절약하기를 바라며 UiPath-SAIv1 덤프 (최신 실제 시험 문제)를 사용 선택하여 현재 최신 79개의 시험 문제와 답을 포함하십시오.
정답:
Explanation:
The "Wait for Classification Validation Task and Resume" activity in UiPath's Document Understanding Framework is primarily used to halt or suspend the workflow until a specified document classification validation task is completed by a human. This activity is part of the broader workflow to ensure that when automatic classification of documents cannot be confidently achieved, a human-in-the-loop (HITL) approach is followed to validate or correct classifications. Once the validation is performed in UiPath's Action Center by a human, the workflow is resumed, ensuring the proper handling of documents that require review and correction.
This is aligned with the design of the Action Center, which is integrated into UiPath's Document Understanding Framework. When dealing with document classification or extraction confidence issues, manual human validation tasks are often required, which is what this activity manages. It facilitates human oversight, preventing the automation from proceeding with potentially incorrect classifications.
Reference from UiPath documentation:
UiPath Action Center explains how humans are involved in validation tasks to handle cases where classification or extraction needs manual review.
Wait for Task and Resume Activity in UiPath Documentation explains how it waits for a task (such as document validation) to be completed in the Action Center before resuming the workflow.
For more details, you can consult the official UiPath documents: UiPath Document Understanding Framework
Wait for Classification Validation Task and Resume
This functionality ensures that incorrect data processing due to automation can be caught and rectified by a human, improving accuracy in document handling workflows.
정답:
Explanation:
According to the UiPath documentation portal1, the Export stage of the Document Understanding Framework is the final stage of the document processing workflow, where the extracted data is converted to a dataset or to a customized format, such as Excel, JSON, or XML. The Export stage enables you to easily export data for training ML models, using the Export files dialog box in Data Manager or Document Manager. The Export stage also allows you to export the schema of the fields and their configurations, which can be imported into a different session. The Export stage supports different export options, such as current search results, all labeled, schema, or all. The Export stage also provides validation rules, such as requiring at least 10 labeled documents or pages for each field, and at least one document for each classification option1. Therefore, option A is the correct answer, as it describes the main function and benefit of the Export stage. Option B is incorrect, as it refers to the Data Validation stage, which is the previous stage of the document processing workflow, where a human can review and correct the extracted data using the Validation Station or the Present Validation Station activities2. Option C is incorrect, as it refers to the Classification stage, which is the second stage of the document processing workflow, where the document is classified as one of the predefined document types using the Classify Document Scope activity and a classifier of choice3. Option D is incorrect, as it refers to the Digitization stage, which is the first stage of the document processing workflow, where the text is extracted out of the image document using OCR (Optical Character Recognition) using the Digitize Document activity and an OCR engine of choice.
References: 1 Document Understanding - Export Documents 2 Document Understanding - Data Validation 3 Document Understanding - Classification Document Understanding - Digitization
정답:
Explanation:
To build custom models supported by AI Center, you can use a Python IDE or an AutoML platform of your choice. A Python IDE is a software application that provides tools and features for writing, editing, debugging, and running Python code. An AutoML platform is a service that automates the process of building and deploying machine learning models, such as data preprocessing, feature engineering, model selection, hyperparameter tuning, and model evaluation. Some examples of Python IDEs are PyCharm, Visual Studio Code, and Jupyter Notebook. Some examples of AutoML platforms are Google Cloud AutoML, Microsoft Azure Machine Learning, and DataRobot.
To use a Python IDE, you need to install the required Python packages and dependencies, write the code for your model, and test it locally. Then, you need to package your model as a zip file that follows the AI Center ML Package structure and requirements. You can then upload the zip file to AI Center and create an ML Skill to deploy and consume your model.
To use an AutoML platform, you need to sign up for the service, upload your data, configure your model settings, and train your model. Then, you need to export your model as a zip file that follows the AI Center ML Package structure and requirements. You can then upload the zip file to AI Center and create an ML Skill to deploy and consume your model.
References: AI Center - Building ML Packages, AI Center - ML Package Structure, AI Center - Creating ML Skills
정답:
Explanation:
When you create a training dataset for document classification or data extraction, you need to split your documents into two subsets: one for training the model and one for evaluating the model. The training subset is used to teach the model how to recognize the patterns and features of your document types and fields. The evaluation subset is used to measure the performance and accuracy of the model on unseen data. The evaluation subset should not be used for training, as this would bias the model and overfit it to the data1.
The recommended split of documents for training and evaluation depends on the size and diversity of your data. However, a general guideline is to use a 70/30 or 80/20 ratio, where 70% or 80% of the documents are used for training and 30% or 20% are used for evaluation. This ensures that the model has enough data to learn from and enough data to test on. For example, if you have 15 documents per vendor, you can use 10 documents for training and 5 documents for evaluation. This would give you a 67/33 split, which is close to the 70/30 ratio. You can also use the Data Manager tool to create and manage your training and evaluation datasets2.
References: 1: Document Understanding - Training High Performing Models 2: Data Manager - Creating a Dataset
정답:
Explanation:
According to the UiPath documentation, the Taxonomy component is used in the Document Understanding Template to define the document types and the fields that are targeted for data extraction for each document type. The Taxonomy component is the metadata that the Document Understanding framework considers in each of its steps, such as document classification and data extraction. The Taxonomy component allows you to create, edit, import, or export the taxonomy of your project, which is a collection of document types and fields that suit your specific objectives. The Taxonomy component also allows you to configure the field types, details, and validations, as well as the supported languages and categories for your documents.
References:
Document Understanding - Taxonomy
Document Understanding - Taxonomy Overview
Document Understanding - Create and Configure Fields
정답:
Explanation:
According to the UiPath Document Understanding Process template, the best way to test the code in a development or testing environment is to create test data based on the use case developed, and use it to test both the existing and the new tests. The test data should include different document types, formats, and scenarios that reflect the real-world data that the process will handle in production. The existing tests are provided by the template and cover the main functionalities and components of the Document Understanding Process, such as digitization, classification, data extraction, validation, and export. The new tests are created by the developer to test the customizations and integrations that are specific to the use case, such as custom extractors, classifiers, or data consumption methods. The test data and the test cases should be updated and maintained throughout the development lifecycle to ensure the quality and reliability of the code.
References:
Document Understanding Process: Studio Template
Document Understanding Process: User Guide
정답:
Explanation:
Entity predictions refer to the process of identifying and highlighting a specific span of text within a communication that represents a value for a predefined entity type. For example, an entity type could be “Organization” and an entity value could be “UiPath”. Entity predictions are made by the platform based on the training data and the rules defined for each entity type. Users can review, accept, reject, or modify the entity predictions using the Classification Station interface12. References: Communications Mining - Reviewing and applying entities, Communications Mining - Predictions - UiPath Documentation Portal.
정답:
Explanation:
According to the UiPath documentation, UiPath Communications Mining is a tool that enables you to analyze text-based communications data, such as customer feedback, support tickets, or chat transcripts, using natural language processing (NLP) and machine learning (ML) techniques1. One of the features of UiPath Communications Mining is the Comparison page, which allows you to compare two cohorts of verbatims based on different criteria, such as date range, source, metadata, or label2. The Comparison page displays the following information for each cohort3: Total verbatim count: The number of verbatims in the cohort.
Proportion for each label: The percentage of verbatims in the cohort that are assigned to each label. A label is a category or a topic that is relevant for the analysis, such as sentiment, intent, or issue type. Labels can be predefined or custom-defined by the user.
Statistical significance: The p-value that indicates whether the difference in proportions between the two cohorts is statistically significant or not. A p-value less than 0.05 means that the difference is unlikely to be due to chance.
The Comparison page also provides a visual representation of the proportions for each label using a
bar chart, and allows the user to drill down into the verbatim content for each label by clicking on
the bars3. Therefore, the correct answer is A.
References:
1: About Communications Mining 2: Communications Mining - Comparing Cohorts 3: Communications Mining - Comparison Page
정답:
Explanation:
According to the UiPath documentation, the field name for a column field in Document Manager does not accept uppercase letters. It can only contain lowercase letters, numbers, underscore _ and dash -12. Therefore, the only option that meets these criteria is D. First_name123. The other options are invalid because they either contain uppercase letters, spaces, or @ symbols, which are not allowed.
References: 1: Document Understanding - Create and Configure Fields 2: Document Understanding - Create & Configure Fields
정답:
Explanation:
According to the UiPath documentation portal1, the RPA Developer is the role that consumes ML Skills within customized workflows in Studio using the ML Skill activity from the UiPath.MLServices.Activities package. The RPA Developer is responsible for designing, developing, testing, and deploying automation workflows using UiPath Studio and other UiPath products. The RPA Developer can use the ML Skill activity to retrieve and call all ML Skills available on the AI Center service and request them within the automation workflows. The ML Skill activity allows the RPA Developer to pass data to the input of the skill, test the skill, and receive the output of the skill as JSON response, status code, and headers2. Therefore, option C is the correct answer, as it describes the role and the activity that are related to consuming ML Skills in Studio. Option A is incorrect, as the Data Scientist is the role that creates and trains ML models using AI Center or other tools, and publishes them as ML Packages or OS Packages1. Option B is incorrect, as the Administrator is the role that manages the AI Center service, such as configuring the infrastructure, setting up the permissions, and monitoring the usage and performance1. Option D is incorrect, as the Process Controller is the role that deploys ML Packages or OS Packages as ML Skills, and manages the versions, the endpoints, and the API keys of the skills1.
References: 1 AI Center - User Personas 2 Activities - ML Skill
정답:
Explanation:
Adding missed labels helps improve the label precision and recall in UiPath Communications Mining. Precision is the percentage of correctly labeled verbatims out of all the verbatims that have the label applied, while recall is the percentage of correctly labeled verbatims out of all the verbatims that should have the label applied. By adding missed labels, you are increasing the recall of the label, as you are reducing the number of false negatives (verbatims that should have the label but do not). This also improves the precision of the label, as you are reducing the noise in the data and making the label more informative and consistent. Adding missed labels is one of the recommended actions that the platform suggests to improve the model rating and performance of the labels.
References: Communications Mining - Training using ‘Check label’ and ‘Missed label’, Communications Mining - Model Rating
정답:
Explanation:
A project in UiPath AI Center is an isolated group of resources (datasets, pipelines, packages, skills, and logs) that you use to build a specific ML solution. You can create, edit, or delete projects from the Projects page or the project’s Dashboard page. However, you can only delete a project if it does not have any package currently deployed in a skill. A package is a versioned and deployable unit of an ML model or an OS script that can be used to create an ML skill. A skill is a consumer-ready, live deployment of a package that can be used in RPA workflows in Studio. If a project has a package deployed in a skill, you need to undeploy the skill first before deleting the project. This is to ensure that you do not accidentally delete a project that is being used by a skill12.
References: 1: AI Center - Managing Projects 2: AI Center - Managing ML Skills
정답:
Explanation:
The Explore phase is the second phase of model training in UiPath Communications Mining, which is a solution that enables the analysis of large volumes of text-based communications using natural language processing and machine learning. The Explore phase builds on the foundations of the taxonomy that was created in the Discover phase by reviewing clusters and searching for different terms and phrases. The objective of the Explore phase is to provide each of the labels or entities that are important for the use case with enough varied and consistent training examples, so that the platform has sufficient training data from which to make accurate predictions across the entire dataset. The Explore phase is the core phase of model training, and requires the most time and effort, but also leads to better model performance and accuracy1.
References: 1: Communications Mining - Explore
정답:
Explanation:
According to the UiPath documentation, a dataset is a folder of storage containing arbitrary sub-folders and files that allows machine learning models in your project to access new data points. You can edit a dataset’s name, description, or content from the Datasets > [Dataset Name] page, by clicking Edit dataset. However, you can only edit a dataset if it is not currently being used in an active pipeline. A pipeline is a sequence of steps that defines how to train, test, and deploy a machine learning model. If a dataset is being used in an active pipeline, you will see a lock icon next to it, indicating that it cannot be edited. You can either wait for the pipeline to finish or stop it before editing the dataset.
References:
AI Center - Managing Datasets
AI Center - About Datasets
AI Center - About Pipelines
정답: 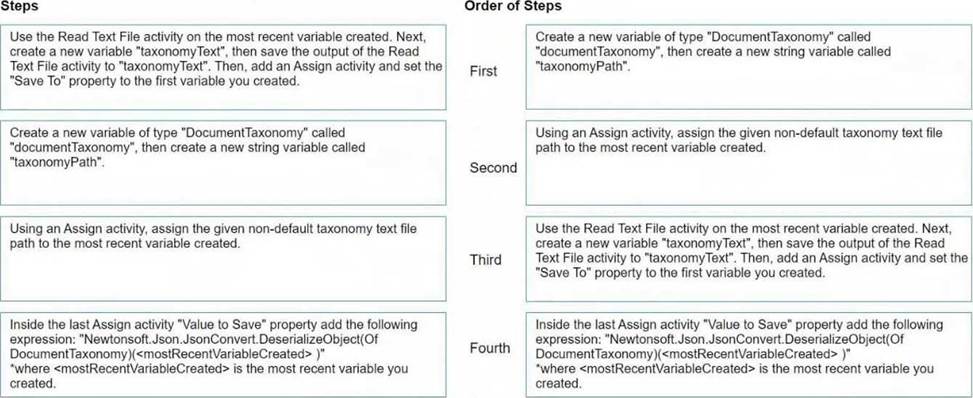
Explanation:
to load a taxonomy from a given non-default location text file into a variable, the order of steps should be as follows:
Create a new variable of type 'DocumentTaxonomy' called 'documentTaxonomy', then create a new string variable called 'taxonomyPath'.
This step involves setting up the necessary variables that will be used in the process. The 'documentTaxonomy' variable will hold the deserialized taxonomy object, and 'taxonomyPath' will store the path to the taxonomy file.
Using an Assign activity, assign the given non-default taxonomy text file path to the most recent variable created.
Here you will assign the path of the taxonomy file to the 'taxonomyPath' variable.
Use the Read Text File activity on the 'taxonomyPath' variable created. Next, create a new variable 'taxonomyText', then save the output of the Read Text File activity to 'taxonomyText'.
This step is where you read the contents of the taxonomy file using the 'Read Text File' activity. The contents are stored in the 'taxonomyText' variable.
Inside the last Assign activity 'Value to Save' property add the following expression:
"Newtonsoft.Json.JsonConvert.DeserializeObject(Of DocumentTaxonomy)(taxonomyText)" where
'taxonomyText' is the text read from the file and 'documentTaxonomy' (the most recent variable created) is the variable you created.
In this final step, you will deserialize the JSON content from the 'taxonomyText' into a 'DocumentTaxonomy' object using the 'JsonConvert.DeserializeObject' method and assign it to the 'documentTaxonomy' variable.
Following these steps in this order will load the taxonomy from a text file into the 'documentTaxonomy' variable in UiPath.