
매달, 우리는 1000명 이상의 사람들이 시험 준비를 잘하고 시험을 잘 통과할 수 있도록 도와줍니다.
Advanced HPE Storage Integrator Solutions Written Exam 온라인 연습
최종 업데이트 시간: 2025년10월11일
당신은 온라인 연습 문제를 통해 HP HPE7-J02 시험지식에 대해 자신이 어떻게 알고 있는지 파악한 후 시험 참가 신청 여부를 결정할 수 있다.
시험을 100% 합격하고 시험 준비 시간을 35% 절약하기를 바라며 HPE7-J02 덤프 (최신 실제 시험 문제)를 사용 선택하여 현재 최신 50개의 시험 문제와 답을 포함하십시오.
정답:
Explanation:
Detailed Explanation:
Rationale for Correct Answer
HPE Peer Persistence is supported over distances of up to 150C200 km, as long as the round-trip latency is ≤10ms. Therefore, even after relocation to 150km, Peer Persistence remains supported provided latency requirements are met.
Distractors:
B: RC (Remote Copy) transport is already the underlying technology, but no change is required.
C: Peer Persistence is already an active-active design; no change to “active” mode is needed.
D: Distance does not exceed the supported range; only latency matters.
Key Concept: Latency <10ms is the critical requirement for Peer Persistence.
Reference: HPE Alletra 6000/Primera Peer Persistence Best Practices.
정답:
Explanation:
Detailed Explanation:
Rationale for Correct Answer
HPE StoreOnce Dual Authorization prevents a single administrator from deleting, expiring, or modifying backup data. Instead, any destructive action requires approval from a second administrator, mitigating insider threats and accidental deletions. This is the correct feature for immutability protection in a replicated StoreOnce environment.
Distractors:
B (CHAP): Used for iSCSI authentication, not backup immutability.
C: Encryption protects data confidentiality, not accidental deletion.
D: Resource restrictions are policy-driven but don’t enforce dual control over destructive actions.
Key Concept: Dual Authorization for ransomware and insider-threat protection on StoreOnce.
Reference: HPE StoreOnce Security Features White Paper.
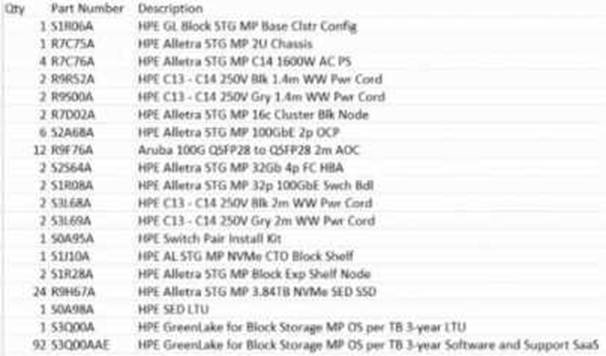
정답:
Explanation:
Detailed Explanation:
Rationale for Correct Answer
The exhibit shows the use of 32Gb FC HBAs and 100GbE switches (Aruba 100G). However, the customer specifically requires 25GbE top-of-rack switches. Therefore, the configuration needs to be corrected to 25GbE networking. The HPE Alletra MP B10000 guarantees 100% data availability SLA, so the primary correction is networking alignment, not drives or financial model.
Distractors:
B: Reducing drives reduces raw capacity below 80TB requirement.
C: GreenLake is a consumption model but not the technical correction required.
D: Aruba 8325 is a core switch option; customer only asked for ToR 25GbE.
Key Concept: Networking alignment with requirements.
Reference: HPE Alletra MP Ordering and Configuration Guide.
정답:
Explanation:
Detailed Explanation:
Rationale for Correct Answer
In Alletra 6000 Peer Persistence environments, operations like resizing Peer Persistence volumes must be performed via the HPE Data Services Cloud Console (DSCC), which manages volume collections and replication consistency groups. Attempting to grow the upstream volume locally will fail because the changes need to propagate across both sites consistently.
Distractors:
A/B: Removing upstream or downstream volumes would break replication and is not required.
D: Expanding in VMware only extends the VMFS datastore, not the underlying replicated volume. Key Concept: Peer Persistence volume resizing is done in DSCC, not local web GUI.
Reference: HPE Alletra 6000 Peer Persistence Configuration and Management Guide.
정답:
Explanation:
Detailed Explanation:
Rationale for Correct Answer
Option B (All) is correct because in an Active Peer Persistence deployment where both arrays and hosts are in close proximity (metro or campus cluster scenario), the hosts should be configured with Host Proximity = All. This ensures that the host (ESX31) can access both arrays symmetrically and concurrently, enabling active-active paths. This is essential to deliver seamless failover and load balancing across the arrays in an HPE Alletra MP Peer Persistence environment. Analysis of Incorrect Options (Distractors):
A (Secondary): This is used for hosts located closer to the secondary array, to bias access toward it in asymmetric deployments. Not applicable here since the hosts are near both arrays.
C (Exclusive): This option assigns the host to a single array exclusively, preventing dual-active access.
This would defeat the purpose of symmetric Peer Persistence.
D (Primary): Similar to Secondary, this biases access to only the primary array, which is not correct when arrays and hosts are in the same site for active-active.
Key Concept:
This question focuses on Host Proximity parameters in HPE Peer Persistence.
Primary/Secondary = asymmetric designs (hosts closer to one array).
All = symmetric design (hosts equidistant to both arrays, enabling active-active).
Exclusive = restricts access to one array only.
Reference: HPE Alletra MP Storage Peer Persistence Best Practices Guide
HPE Primera/Alletra Remote Copy and Peer Persistence Technical White Paper VMware Metro Storage Cluster with HPE Peer Persistence Implementation Notes
정답:
Explanation:
Detailed Explanation:
Rationale for Correct Answer
HPE CloudPhysics provides comprehensive environment assessment and competitive sizing for virtualized environments (VMware, Hyper-V, etc.). The CloudPhysics collector (available as a .vhdx for Hyper-V) is deployed into the cluster to gather metrics on CPU, memory, storage IOPS/latency, and utilization trends. These analytics feed into the sizing of HPE storage solutions.
Distractors:
B: InfoSight sizing tools work with HPE systems, not competitive 3rd-party storage like Pure.
C: SAF is a manual assessment requiring email submission and is not the correct modern method for this case.
D: NinjaProtected applies to backup analysis, not production Hyper-V cluster sizing.
Key Concept: CloudPhysics.vhdx collector for Hyper-V sizing with 3rd-party infrastructure.
Reference: HPE CloudPhysics Assessment Guide.
정답:
Explanation:
Detailed Explanation:
Rationale for Correct Answer
Zerto, now part of HPE, provides continuous data protection (CDP) with near-zero RPOs and very low RTOs. It supports VMware workloads, as well as hybrid cloud deployments with AWS and Azure. Zerto is specifically designed for disaster recovery orchestration, enabling automated failover, failback, and application-consistent protection across sites and cloud environments.
Distractors:
B (CommVault): Primarily a backup/recovery and data management platform ― RPOs are not near-zero.
C (Cohesity): Strong in backup, secondary storage, and ransomware recovery, but not near-zero RPO DR orchestration.
D (SimpliVity): Hyperconverged infrastructure with built-in backup, but not optimized for large-scale multi-cloud DR.
Key Concept: Continuous Data Protection (Zerto) for hybrid/multi-cloud disaster recovery.
Reference: HPE Zerto DR for Hybrid and Multi-cloud Environments.
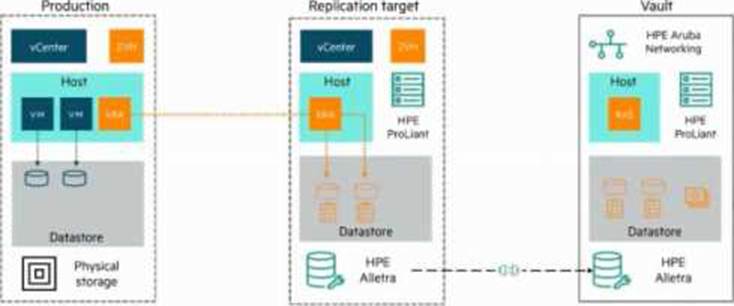
정답:
Explanation:
Detailed Explanation:
Rationale for Correct Answer
In the Zerto Vault architecture, production workloads replicate continuously to a Replication Target (secondary site). From there, data is further replicated periodically and encrypted into the Vault (air-gapped, isolated site). This two-step process ensures ransomware resilience and immutability, as the Vault acts as a hardened third copy.
Distractors:
A: Production-to-replication target traffic is continuous synchronous/asynchronous replication, not periodic. Periodic replication applies to Replication Target → Vault.
C: The Resilience Automation Server (RAS) is responsible for orchestrating failover and immutability enforcement, but it does not control port access between production and replication target.
D: Snapshots of Zerto components are not what is replicated ― it’s application data VMs/volumes. The Vault ensures immutability of replicated data, not ZVM components.
Key Concept: Zerto Vault = encrypted, periodic replication from replication target to immutable vault.
Reference: HPE Zerto Vault Architecture White Paper, HPE Ransomware Recovery Solutions.
정답:
Explanation:
Detailed Explanation:
Rationale for Correct Answer
HPE is one of the leading infrastructure providers for SAP HANA, with ~40% of global SAP HANA deployments running on HPE platforms (ProLiant, Alletra, Nimble/Primera for storage). This is an official HPE statistic repeatedly cited in white papers and customer references.
Distractors:
A: SAP HANA licensing is provided directly by SAP, not custom-issued by HPE.
B: Licensing costs are tied to SAP metrics (memory size), not Alletra storage type.
C: “77% prefer” is a marketing exaggeration and not the accurate documented figure. Key Concept: HPE’s strong positioning in SAP HANA infrastructure market share.
Reference: HPE SAP HANA Solutions Overview, HPE Global SAP HANA Customer Reference Sheet.
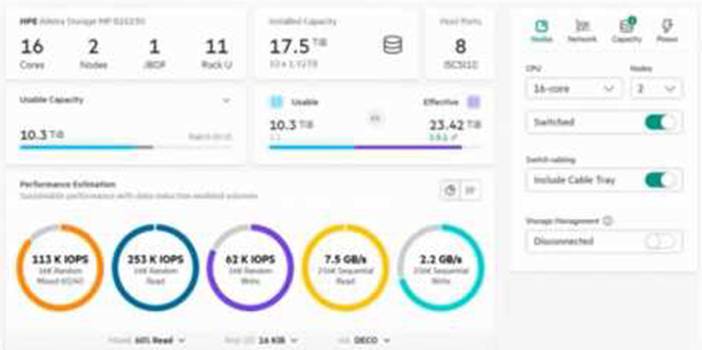
정답:
Explanation:
Detailed Explanation:
Rationale for Correct Answer
From the exhibit, the system shows maximum estimated IOPS performance (over 250K IOPS read, 115K IOPS mixed, 62K write). These values align with HPE’s published performance specifications for this model with full cores enabled. The network interface count and disk count are balanced relative to controller capability. Therefore, no further upgrades are required to achieve maximum performance.
Distractors:
A: Adding NICs/HBAs may improve throughput but will not exceed controller-bound IOPS.
B: Adding disks increases capacity, not peak IOPS, as performance is primarily controller-driven.
D: The system already matches controller capability; upgrading cores is not an option in Alletra MP B10000 mid-range systems.
Key Concept: Understanding performance sizing based on controller and architecture limits, not just capacity or NICs.
Reference: HPE Alletra MP Performance and Sizing Guide.
정답:
Explanation:
Detailed Explanation:
Rationale for Correct Answer
After installing the HPE CSI driver and creating backend secrets, the next critical step is to define a StorageClass that references the backend driver and parameters. Without the StorageClass, Kubernetes cannot dynamically provision PersistentVolumes (PVs). Once the StorageClass is created, workloads can request storage using PersistentVolumeClaims (PVCs).
Distractors:
A: Helm repo update only refreshes Helm charts; it does not enable CSI provisioning.
B: A PVC requires a StorageClass to bind dynamically ― it cannot be created successfully beforehand.
C: Manually creating PVs is possible, but not the HPE best practice with CSI, which relies on StorageClass for dynamic provisioning.
Key Concept: Kubernetes CSI workflow: Secret → StorageClass → PVC → Pod.
정답:
Explanation:
Detailed Explanation:
Rationale for Correct Answer
The SAF (Storage Assessment Framework) requires engineers to manually email the collected assessment data to HPE for processing. This is different from fully automated tools like CloudPhysics or Backup assessments that integrate directly with portals. This distinction is important for new engineers performing customer assessments.
Distractors:
A: Backup assessments are usually tool-driven (StoreOnce, RMC, etc.) and automated.
C: Non-HPE assessments are outside scope and not part of HPE standard process.
D: CloudPhysics is fully automated and cloud-based ― no manual email required. Key Concept: SAF = requires manual email submission to HPE.
Reference: HPE Internal Assessment and Sizing Tools Guide.
정답:
Explanation:
Detailed Explanation:
Rationale for Correct Answer
FC-FC routing (also known as Fibre Channel Routing / LSANs on B-Series switches) allows replication
between separate SAN fabrics without merging them. This supports disaster recovery scenarios
while preserving fabric isolation, exactly matching the bank’s requirement.
Distractors:
A: FCIP tunnels extend Fibre Channel over IP networks, but this typically merges SAN domains.
C: NPIV (N_Port ID Virtualization) allows multiple virtual WWNs per port, not cross-fabric replication.
D: Fabric partitioning is zoning and segmentation within a single fabric, not between independent fabrics.
Key Concept: FC-FC routing on Brocade (B-Series) for SAN isolation with replication.
Reference: HPE B-Series SAN Design Guide, Brocade FCR/LSAN Concepts.
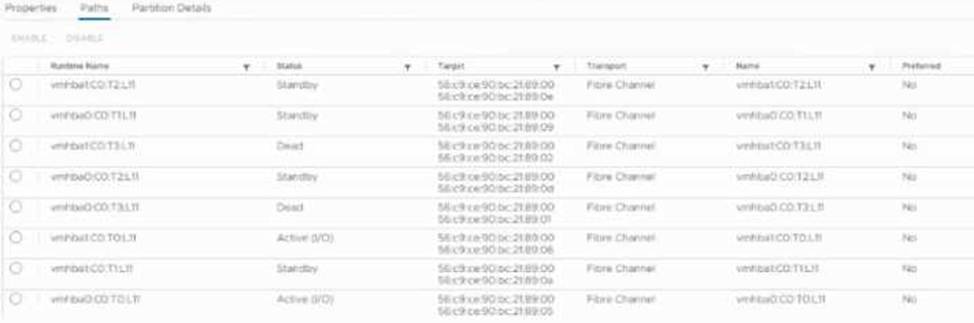
정답:
Explanation:
Detailed Explanation:
Rationale for Correct Answer
In the exhibit, several paths show “Standby” and some appear “Dead”, while only a subset is Active (0). This typically indicates that one storage controller may be missing or offline, which reduces redundancy and can cause performance degradation. In a healthy Peer Persistence environment, both controllers should present active and non-optimized paths.
Distractors:
A & B: Having multiple active paths does not inherently reduce performance; in fact, MPIO load balances traffic. The issue here is path failures, not excessive active paths. Key Concept: MPIO pathing in HPE Peer Persistence and controller health.
Reference: HPE Alletra 6000 Peer Persistence Implementation Guide.
정답:
Explanation:
Detailed Explanation:
Rationale for Correct Answer
When using Zerto Move, unlike a typical disaster recovery failover, the migration process allows the source VMs to be retained after cutover. This is useful when testing or validating the migration. In contrast, failover scenarios typically assume the source environment has failed or is decommissioned. Therefore, keeping source VMs is a differentiator for Move.
Distractors:
A: Checkpoints and RPO are controlled by Zerto replication but are not selectable per migration cutover in this way.
B: Source VMs are not deleted automatically; this is intentionally avoided to allow rollback.
D: While Zerto does provide low RPO/RTO (seconds to minutes), this applies mainly to DR failover, not migration cutovers.
Key Concept: Zerto Move vs Zerto Failover semantics.
Reference: HPE Zerto Move Technical Overview, HPE Zerto Replication & Migration Best Practices.