
매달, 우리는 1000명 이상의 사람들이 시험 준비를 잘하고 시험을 잘 통과할 수 있도록 도와줍니다.
Designing and Implementing Cloud-Native Applications Using Microsoft Azure Cosmos DB 온라인 연습
최종 업데이트 시간: 2025년10월13일
당신은 온라인 연습 문제를 통해 Microsoft DP-420 시험지식에 대해 자신이 어떻게 알고 있는지 파악한 후 시험 참가 신청 여부를 결정할 수 있다.
시험을 100% 합격하고 시험 준비 시간을 35% 절약하기를 바라며 DP-420 덤프 (최신 실제 시험 문제)를 사용 선택하여 현재 최신 51개의 시험 문제와 답을 포함하십시오.
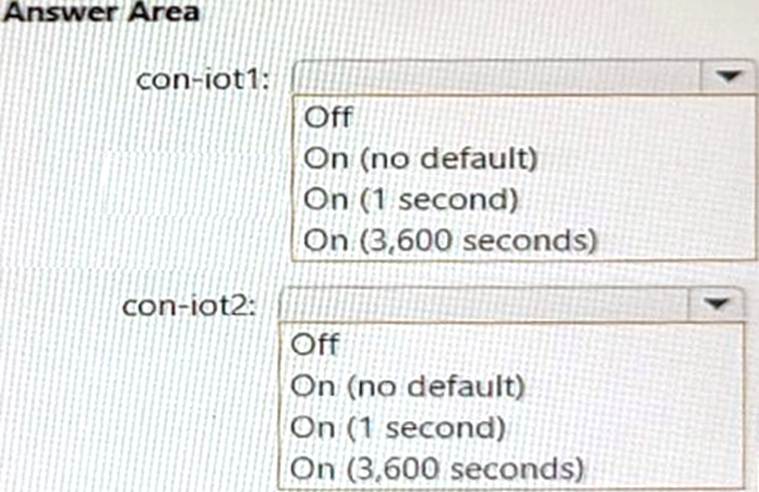
정답: 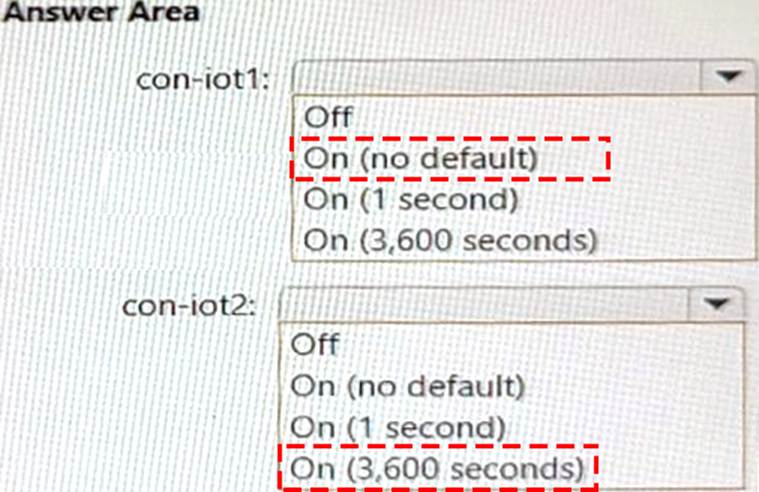
Explanation:
Box 1 = On (no default)
For con-iot1, you need to configure the default TTL setting to On (no default), which means that items in this container do not expire by default, but you can override the TTL value on a per-item basis. This meets the requirement of retaining all telemetry data unless overridden1. Box 2 = On (3600 seconds)
For con-iot2, you need to configure the default TTL setting to On (3600 seconds), which means that items in this container will expire 3600 seconds (one hour) after their last modified time. This meets the requirement of deleting all telemetry data older than one hour1.
정답:
Explanation:
Reference: https://github.com/microsoft/MCW-Cosmos-DB-Real-Time-Advanced-Analytics/blob/main/Hands-on%20lab/HOL%20step-by%20step%20-%20Cosmos%20DB%20real-time%20advanced%20analytics.md


정답: 
Explanation:
Box 1: No
Each physical partition should have its own index, but since no index is used, the query is not cross-partition.
Box 2: No
Index utilization is 0% and Index Look up time is also zero.
Box 3: Yes
A partition key index will be created, and the query will perform across the partitions.
Reference: https://docs.microsoft.com/en-us/azure/cosmos-db/sql/how-to-query-container


정답: 
Explanation:
Box 1: Serverless capacity mode
Azure Cosmos DB serverless best fits scenarios where you expect intermittent and unpredictable traffic with long idle times. Because provisioning capacity in such situations isn't required and may be cost-prohibitive, Azure Cosmos DB serverless should be considered in the following use-cases: Getting started with Azure Cosmos DB
Running applications with bursty, intermittent traffic that is hard to forecast, or low (<10%) average-to-peak traffic ratio
Developing, testing, prototyping and running in production new applications where the traffic pattern is unknown
Integrating with serverless compute services like Azure Functions
Box 2: Provisioned throughput capacity mode and autoscale throughput
The use cases of autoscale include:
Variable or unpredictable workloads: When your workloads have variable or unpredictable spikes in usage, autoscale helps by automatically scaling up and down based on usage. Examples include retail websites that have different traffic patterns depending on seasonality; IOT workloads that have spikes at various times during the day; line of business applications that see peak usage a few times a month or year, and more. With autoscale, you no longer need to manually provision for peak or average capacity.
Reference:
https://docs.microsoft.com/en-us/azure/cosmos-db/serverless
https://docs.microsoft.com/en-us/azure/cosmos-db/provision-throughput-autoscale#use-cases-of-autoscale
정답:
Explanation:
Azure Cosmos DB supports queries with parameters expressed by the familiar @ notation. Parameterized SQL provides robust handling and escaping of user input, and prevents accidental exposure of data through SQL injection.
For example, you can write a query that takes lastName and address.state as parameters, and execute it for various values of lastName and address.state based on user input. SELECT *
FROM Families f
WHERE f.lastName = @lastName AND f.address.state = @addressState
Reference: https://docs.microsoft.com/en-us/azure/cosmos-db/sql/sql-query-parameterized-queries
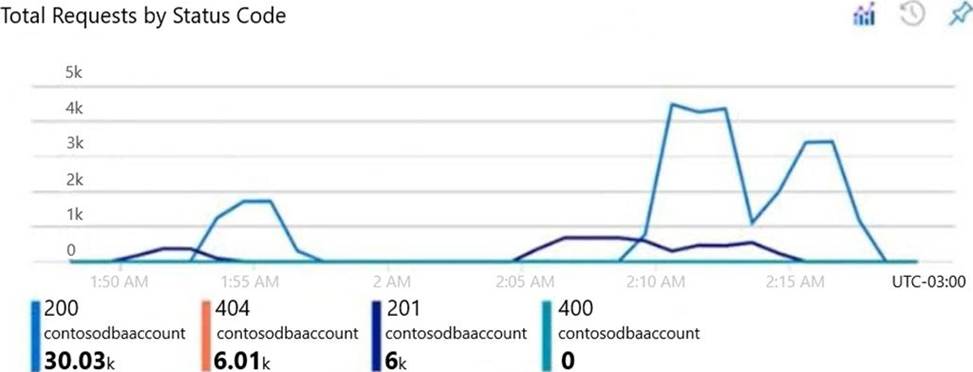

정답: 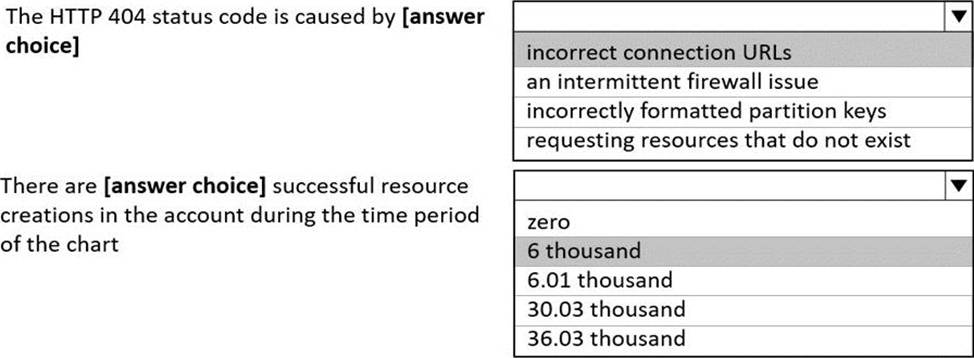
Explanation:
Box 1: incorrect connection URLs
400 Bad Request: Returned when there is an error in the request URI, headers, or body. The response body will contain an error message explaining what the specific problem is.
The HyperText Transfer Protocol (HTTP) 400 Bad Request response status code indicates that the server cannot or will not process the request due to something that is perceived to be a client error (for example, malformed request syntax, invalid request message framing, or deceptive request routing).
Box 2: 6 thousand
201 Created: Success on PUT or POST. Object created or updated successfully.
Note:
200 OK: Success on GET, PUT, or POST. Returned for a successful response.
404 Not Found: Returned when a resource does not exist on the server. If you are managing or querying an index, check the syntax and verify the index name is specified correctly.
Reference: https://docs.microsoft.com/en-us/rest/api/searchservice/http-status-codes
정답:
Explanation:
Reference: https://docs.microsoft.com/en-us/azure/cosmos-db/provision-account-continuous-backup
정답:
Explanation:
The following are the operation names in diagnostic logs for different operations:
RegionAddStart, RegionAddComplete
RegionRemoveStart, RegionRemoveComplete
AccountDeleteStart, AccountDeleteComplete
RegionFailoverStart, RegionFailoverComplete AccountCreateStart, AccountCreateComplete *AccountUpdateStart*, AccountUpdateComplete VirtualNetworkDeleteStart, VirtualNetworkDeleteComplete DiagnosticLogUpdateStart, DiagnosticLogUpdateComplete
Reference: https://docs.microsoft.com/en-us/azure/cosmos-db/audit-control-plane-logs
정답:
Explanation:
Cosmos DB Operator: Can provision Azure Cosmos accounts, databases, and containers. Cannot
access any data or use Data Explorer.
Incorrect Answers:
B: DocumentDB Account Contributor can manage Azure Cosmos DB accounts. Azure Cosmos DB is formerly known as DocumentDB.
C: DocumentDB Account Contributor: Can manage Azure Cosmos DB accounts.
Reference: https://docs.microsoft.com/en-us/azure/cosmos-db/role-based-access-control
정답:
Explanation:
Batch size: An integer that represents how many objects are being written to Cosmos DB collection in each batch. Usually, starting with the default batch size is sufficient. To further tune this value, note: Cosmos DB limits single request's size to 2MB. The formula is "Request Size = Single Document Size * Batch Size". If you hit error saying "Request size is too large", reduce the batch size value.
The larger the batch size, the better throughput the service can achieve, while make sure you allocate enough RUs to empower your workload. Incorrect Answers:
A: Throughput: Set an optional value for the number of RUs you'd like to apply to your CosmosDB collection for each execution of this data flow. Minimum is 400.
B: Write throughput budget: An integer that represents the RUs you want to allocate for this Data Flow write operation, out of the total throughput allocated to the collection.
D: Collection action: Determines whether to recreate the destination collection prior to writing. None: No action will be done to the collection.
Recreate: The collection will get dropped and recreated
Reference: https://docs.microsoft.com/en-us/azure/data-factory/connector-azure-cosmos-db
정답:
Explanation:
C: Avro is binary format, while JSON is text.
F: Kafka Connect for Azure Cosmos DB is a connector to read from and write data to Azure Cosmos DB. The Azure Cosmos DB sink connector allows you to export data from Apache Kafka topics to an Azure Cosmos DB database. The connector polls data from Kafka to write to containers in the database based on the topics subscription.
D: Create the Azure Cosmos DB sink connector in Kafka Connect. The following JSON body defines config for the sink connector.
Extract:
"connector.class": "com.azure.cosmos.kafka.connect.sink.CosmosDBSinkConnector",
"key.converter": "org.apache.kafka.connect.json.AvroConverter"
"connect.cosmos.containers.topicmap": "hotels#kafka" Incorrect Answers:
B: JSON is plain text. Note, full example:
{
"name": "cosmosdb-sink-connector",
"config": {
"connector.class": "com.azure.cosmos.kafka.connect.sink.CosmosDBSinkConnector",
"tasks.max": "1",
"topics": [ "hotels" ],
"value.converter": "org.apache.kafka.connect.json.AvroConverter",
"value.converter.schemas.enable": "false",
"key.converter": "org.apache.kafka.connect.json.AvroConverter",
"key.converter.schemas.enable": "false",
"connect.cosmos.connection.endpoint": "https://<cosmosinstance-name>.documents.azure.com:443/",
"connect.cosmos.master.key": "<cosmosdbprimarykey>",
"connect.cosmos.databasename": "kafkaconnect",
"connect.cosmos.containers.topicmap": "hotels#kafka"
}
}
Reference:
https://docs.microsoft.com/en-us/azure/cosmos-db/sql/kafka-connector-sink
https://www.confluent.io/blog/kafka-connect-deep-dive-converters-serialization-explained/
정답:
Explanation:
Reference: https://docs.microsoft.com/en-us/azure/cosmos-db/how-to-setup-cmk


정답: 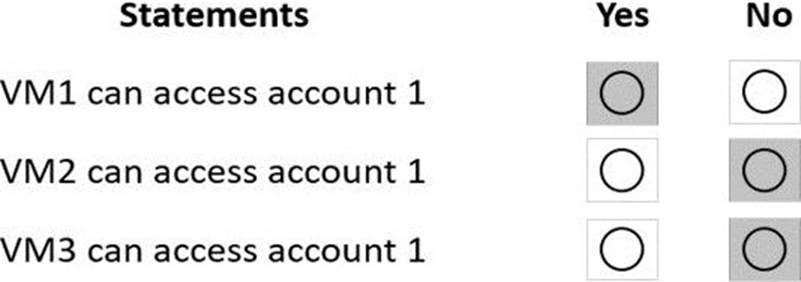
Explanation:
Box 1: Yes
VM1 is on vnet1.subnet1 which has the Endpoint Status enabled.
Box 2: No
Only virtual network and their subnets added to Azure Cosmos account have access. Their peered VNets cannot access the account until the subnets within peered virtual networks are added to the account.
Box 3: No
Only virtual network and their subnets added to Azure Cosmos account have access.
Reference: https://docs.microsoft.com/en-us/azure/cosmos-db/how-to-configure-vnet-service-endpoint
정답: 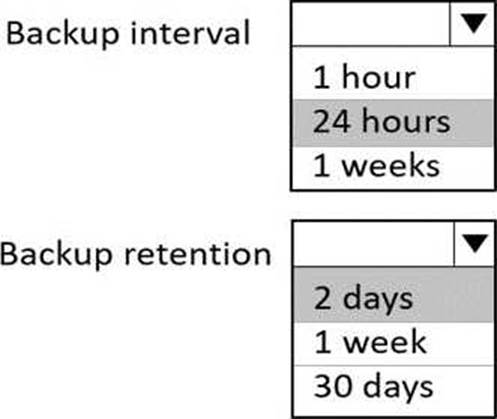
정답:
Explanation:
If a query has a filter with two or more properties, adding a composite index will improve performance.
Consider the following query:
SELECT * FROM c WHERE c.name = “Tim” and c.age > 18
In the absence of a composite index on (name ASC, and age ASC), we will utilize a range index for this query. We can improve the efficiency of this query by creating a composite index for name and age. Queries with multiple equality filters and a maximum of one range filter (such as >,<, <=, >=, !=) will utilize the composite index.
Reference: https://azure.microsoft.com/en-us/blog/three-ways-to-leverage-composite-indexes-in-azure-cosmos-db/