
매달, 우리는 1000명 이상의 사람들이 시험 준비를 잘하고 시험을 잘 통과할 수 있도록 도와줍니다.
Databricks Certified Generative AI Engineer Associate 온라인 연습
최종 업데이트 시간: 2025년10월10일
당신은 온라인 연습 문제를 통해 Databricks Databricks Generative AI Engineer Associate 시험지식에 대해 자신이 어떻게 알고 있는지 파악한 후 시험 참가 신청 여부를 결정할 수 있다.
시험을 100% 합격하고 시험 준비 시간을 35% 절약하기를 바라며 Databricks Generative AI Engineer Associate 덤프 (최신 실제 시험 문제)를 사용 선택하여 현재 최신 45개의 시험 문제와 답을 포함하십시오.
정답:
Explanation:
In this scenario, the Generative AI Engineer needs to design a system that can handle different types of queries about the monster truck team. The queries may involve text-based information, API lookups for event dates, or table queries for standings. The best solution is to implement a tool-based agent system.
Here’s how option B works, and why it’s the most appropriate answer:
System Design Using Agent-Based Model:
In modern agent-based LLM systems, you can design a system where the LLM (Large Language Model) acts as a central orchestrator. The model can "decide" which tools to use based on the query. These tools can include API calls, table lookups, or natural language searches. The system should contain a system prompt that informs the LLM about the available tools.
System Prompt Listing Tools:
By creating a well-crafted system prompt, the LLM knows which tools are at its disposal. For instance, one tool may query an external API for event dates, another might look up standings in a database, and a third may involve searching a vector database for general text-based information. The agent will be responsible for calling the appropriate tool depending on the query.
Agent Orchestration of Calls:
The agent system is designed to execute a series of steps based on the incoming query. If a user asks for the next event date, the system will recognize this as a task that requires an API call. If the user asks about standings, the agent might query the appropriate table in the database. For text-based questions, it may call a search function over ingested data. The agent orchestrates this entire process, ensuring the LLM makes calls to the right resources dynamically. Generative AI Tools and Context:
This is a standard architecture for integrating multiple functionalities into a system where each query requires different actions. The core design in option B is efficient because it keeps the system modular and dynamic by leveraging tools rather than overloading the LLM with static information in a system prompt (like option D).
Why Other Options Are Less Suitable:
A (RAG Architecture): While relevant, simply ingesting PDFs into a vector store only helps with text-based retrieval. It wouldn’t help with API lookups or table queries.
C (Conditional Logic with RAG/API/TABLE): Although this approach works, it relies heavily on manual text parsing and might introduce complexity when scaling the system.
D (System Prompt with Event Dates and Standings): Hardcoding dates and table information into a system prompt isn’t scalable. As the standings or events change, the system would need constant updating, making it inefficient.
By bundling multiple tools into a single agent-based system (as in option B), the Generative AI Engineer can best handle the diverse requirements of this system.
정답:
Explanation:
Problem Context: The task is to build an LLM-based question-answering application that integrates new documents frequently with minimal costs and development efforts.
Explanation of Options:
Option A: Utilizes a prompt and a retriever, with the retriever output being fed into the LLM. This setup is efficient because it dynamically updates the data pool via the retriever, allowing the LLM to provide up-to-date answers based on the latest documents without needing to frequently retrain the model. This method offers a balance of cost-effectiveness and functionality.
Option B: Requires frequent retraining of the LLM, which is costly and labor-intensive.
Option C: Only involves prompt engineering and an LLM, which may not adequately handle the requirement for incorporating new documents unless it’s part of an ongoing retraining or updating mechanism, which would increase costs.
Option D: Involves an agent and a fine-tuned LLM, which could be overkill and lead to higher development and operational costs.
Option A is the most suitable as it provides a cost-effective, minimal development approach while ensuring the application remains up-to-date with new information.
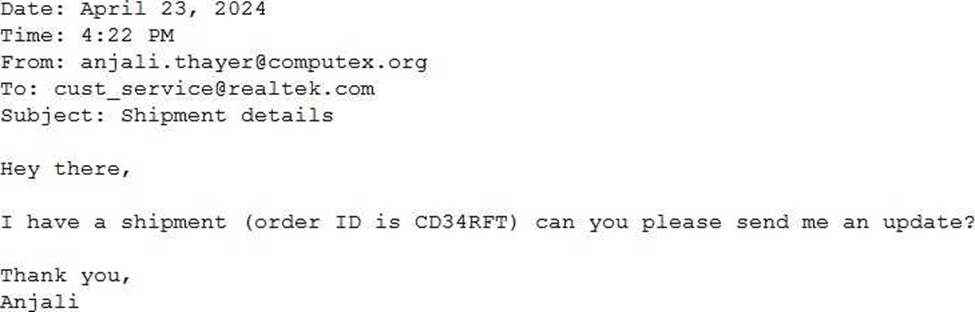
정답:
Explanation:
Problem Context: The goal is to parse emails to extract certain pieces of information and output this in a structured JSON format. Clarity and specificity in the prompt design will ensure higher accuracy in the LLM’s responses.
Explanation of Options:
Option A: Provides a general guideline but lacks an example, which helps an LLM understand the exact format expected.
Option B: Includes a clear instruction and a specific example of the output format. Providing an example is crucial as it helps set the pattern and format in which the information should be structured, leading to more accurate results.
Option C: Does not specify that the output should be in JSON format, thus not meeting the requirement.
Option D: While it correctly asks for JSON format, it lacks an example that would guide the LLM on how to structure the JSON correctly.
Therefore, Option B is optimal as it not only specifies the required format but also illustrates it with an example, enhancing the likelihood of accurate extraction and formatting by the LLM.
정답:
Explanation:
Problem Context: The Generative AI Engineer needs a model for a Retrieval-Augmented Generation (RAG) application that provides high-quality answers, where latency and throughput are not major concerns. The key factors are confidentiality and sensitivity of the data, as well as the requirement for all processing to be confined to internal resources without external data transmission.
Explanation of Options:
Option A: Dolly 1.5B: This model does not typically support RAG applications as it's more focused on image generation tasks.
Option B: OpenAI GPT-4: While GPT-4 is powerful for generating responses, its standard deployment involves cloud-based processing, which could violate the confidentiality requirements due to external data transmission.
Option C: BGE-large: The BGE (Big Green Engine) large model is a suitable choice if it is configured to operate on-premises or within a secure internal environment that meets regulatory requirements. Assuming this setup, BGE-large can provide high-quality answers while ensuring that data is not transmitted to third parties, thus aligning with the project's sensitivity and confidentiality needs.
Option D: Llama2-70B: Similar to GPT-4, unless specifically set up for on-premises use, it generally relies on cloud-based services, which might risk confidential data exposure.
Given the sensitivity and confidentiality concerns, BGE-large is assumed to be configurable for secure internal use, making it the optimal choice for this scenario.
정답:
Explanation:
Problem Context: The Generative AI Engineer needs a prompt that will enable an LLM trained on customer call transcripts to classify and respond correctly regarding product availability. The desired response should clearly indicate whether a product is "In Stock" or "Out of Stock," and it should be formatted in a way that is structured and easy to parse programmatically, such as JSON. Explanation of Options:
Option A: Respond with “In Stock” if the customer asks for a product. This prompt is too generic and does not specify how to handle the case when a product is not available, nor does it provide a structured output format.
Option B: This option is correctly formatted and explicit. It instructs the LLM to respond based on the availability mentioned in the customer call transcript and to format the response in JSON. This structure allows for easy integration into systems that may need to process this information automatically, such as customer service dashboards or databases.
Option C: Respond with “Out of Stock” if the customer asks for a product. Like option A, this prompt is also insufficient as it only covers the scenario where a product is unavailable and does not provide a structured output.
Option D: While this prompt correctly specifies how to respond based on product availability, it lacks the structured output format, making it less suitable for systems that require formatted data for further processing.
Given the requirements for clear, programmatically usable outputs, Option B is the optimal choice because it provides precise instructions on how to respond and includes a JSON format example for structuring the output, which is ideal for automated systems or further data handling.
정답:
Explanation:
When addressing concerns of hallucination and data leakage in an LLM application for internal company policies, fine-tuning the model on internal data with the hope it learns data boundaries can be problematic:
Risk of Data Leakage: Fine-tuning on sensitive or confidential data does not guarantee that the model will not inadvertently include or reference this data in its outputs. There’s a risk of overfitting to the specific data details, which might lead to unintended leakage.
Hallucination: Fine-tuning does not necessarily mitigate the model's tendency to hallucinate; in fact, it might exacerbate it if the training data is not comprehensive or representative of all potential queries.
Better Approaches:
A, C, and D involve setting up operational safeguards and constraints that directly address data leakage and ensure responses are aligned with specific user needs and security levels.
Fine-tuning lacks the targeted control needed for such sensitive applications and can introduce new risks, making it an unsuitable approach in this context.
정답:
Explanation:
To mitigate the issue of the LLM including explanations of how summaries are generated in its output, the best approach is to adjust the training or prompt structure.
Here’s why Option D is effective:
Few-shot Learning: By providing specific examples of how the desired output should look (i.e., just the summary without explanation), the model learns the preferred format. This few-shot learning approach helps the model understand not only what content to generate but also how to format its responses.
Prompt Engineering: Adjusting the user prompt to specify the desired output format clearly can guide the LLM to produce summaries without additional explanatory text. Effective prompt design is crucial in controlling the behavior of generative models.
Why Other Options Are Less Suitable:
A: While technically feasible, splitting the output by newline and truncating could lead to loss of important content or create awkward breaks in the summary.
B: Tuning chunk sizes or changing embedding models does not directly address the issue of the model's tendency to generate explanations along with summaries.
C: Revisiting document ingestion logic ensures accurate source data but does not influence how the model formats its output.
By using few-shot examples and refining the prompt, the engineer directly influences the output format, making this approach the most targeted and effective solution.





정답:
Explanation:
To fix the error in the LangChain code provided for using a simple prompt template, the correct approach is Option C. Here's a detailed breakdown of why Option C is the right choice and how it addresses the issue:
Proper Initialization: In Option C, the LLMChain is correctly initialized with the LLM instance specified as OpenAI(), which likely represents a language model (like GPT) from OpenAI. This is crucial as it specifies which model to use for generating responses.
Correct Use of Classes and Methods:
The PromptTemplate is defined with the correct format, specifying that adjective is a variable within the template. This allows dynamic insertion of values into the template when generating text.
The prompt variable is properly linked with the PromptTemplate, and the final template string is passed correctly.
The LLMChain correctly references the prompt and the initialized OpenAI() instance, ensuring that the template and the model are properly linked for generating output.
Why Other Options Are Incorrect:
Option A: Misuses the parameter passing in generate method by incorrectly structuring the dictionary.
Option B: Incorrectly uses prompt.format method which does not exist in the context of LLMChain
and PromptTemplate configuration, resulting in potential errors.
Option D: Incorrect order and setup in the initialization parameters for LLMChain, which would likely lead to a failure in recognizing the correct configuration for prompt and LLM usage.
Thus, Option C is correct because it ensures that the LangChain components are correctly set up and integrated, adhering to proper syntax and logical flow required by LangChain's architecture. This setup avoids common pitfalls such as type errors or method misuses, which are evident in other options.
정답:
Explanation:
Problem Context: When using data to train a model, it’s essential to ensure compliance with licensing to avoid legal risks. Legal issues can arise from using data without permission, especially when it comes from third-party sources.
Explanation of Options:
Option A: Reaching out to data curators before using the data is an appropriate action. This allows you to ensure you have permission or understand the licensing terms before starting to use the data in your model.
Option B: Using original data that you personally created is always a safe option. Since you have full ownership over the data, there are no legal risks, as you control the licensing.
Option C: Using data that is explicitly labeled with an open license and adhering to the license terms is a correct and recommended approach. This ensures compliance with legal requirements.
Option D: Reaching out to the data curators after you have already started using the trained model is not appropriate. If you’ve already used the data without understanding its licensing terms, you may have already violated the terms of use, which could lead to legal complications. It’s essential to clarify the licensing terms before using the data, not after.
Thus, Option D is not appropriate because it could expose you to legal risks by using the data without first obtaining the proper licensing permissions.
정답:
Explanation:
Problem Context: The Generative AI Engineer needs a tool to build a multi-step LLM-based workflow. This type of workflow often involves chaining multiple steps together, such as query generation, retrieval of information, response generation, and post-processing, with LLMs integrated at several points.
Explanation of Options:
Option A: Pandas: Pandas is a powerful data manipulation library for structured data analysis, but it is not designed for managing or orchestrating multi-step workflows, especially those involving LLMs.
Option B: TensorFlow: TensorFlow is primarily used for training and deploying machine learning models, especially deep learning models. It is not designed for orchestrating multi-step tasks in LLM-based workflows.
Option C: PySpark: PySpark is a distributed computing framework used for large-scale data processing. While useful for handling big data, it is not specialized for chaining LLM-based operations.
Option D: LangChain: LangChain is a purpose-built framework designed specifically for orchestrating multi-step workflows with large language models (LLMs). It enables developers to easily chain different tasks, such as retrieving documents, summarizing information, and generating responses, all in a structured flow. This makes it the best tool for building complex LLM-based workflows. Thus, LangChain is the most suitable library for creating multi-step LLM-based workflows.
정답:
Explanation:
In the context of developing a chatbot for a company's internal HelpDesk Call Center, the key is to select data sources that provide the most contextual and detailed information about the issues being addressed. This includes identifying the root cause and suggesting resolutions.
The two most appropriate sources from the list are:
Call Detail (Option D):
Contents: This Delta table includes a snapshot of all call details updated hourly, featuring essential fields like root_cause and resolution.
Relevance: The inclusion of root_cause and resolution fields makes this source particularly valuable, as it directly contains the information necessary to understand and resolve the issues discussed in the calls. Even if some records are incomplete, the data provided is crucial for a chatbot aimed at speeding up resolution identification.
Transcript Volume (Option E):
Contents: This Unity Catalog Volume contains recordings in .wav format and text transcripts in .txt files.
Relevance: The text transcripts of call recordings can provide in-depth context that the chatbot can analyze to understand the nuances of each issue. The chatbot can use natural language processing techniques to extract themes, identify problems, and suggest resolutions based on previous similar interactions documented in the transcripts.
Why Other Options Are Less Suitable:
A (Call Cust History): While it provides insights into customer interactions with the HelpDesk, it focuses more on the usage metrics rather than the content of the calls or the issues discussed.
B (Maintenance Schedule): This data is useful for understanding when services may not be available but does not contribute directly to resolving user issues or identifying root causes.
C (Call Rep History): Though it offers data on call durations and start times, which could help in assessing performance, it lacks direct information on the issues being resolved.
Therefore, Call Detail and Transcript Volume are the most relevant data sources for a chatbot designed to assist with identifying and resolving issues in a HelpDesk Call Center setting, as they provide direct and contextual information related to customer issues.
정답:
Explanation:
For a small, cost-conscious startup in the cancer research field, choosing a domain-specific and smaller LLM is the most effective strategy.
Here's why B is the best choice:
Domain-specific performance: A smaller LLM that has been fine-tuned for the domain of cancer research will outperform a general-purpose LLM for specialized queries. This ensures high-quality responses without needing to rely on a large, expensive LLM.
Cost-efficiency: Smaller models are cheaper to run, both in terms of compute resources and API usage costs. A domain-specific smaller LLM can deliver good quality responses without the need for the extensive computational power required by larger models.
Focused knowledge: In a specialized field like cancer research, having an LLM tailored to the subject matter provides better relevance and accuracy for queries, while keeping costs low. Large, general-purpose LLMs may provide irrelevant information, leading to inefficiency and higher costs.
This approach allows the startup to balance quality, cost, and customer satisfaction effectively, making it the most suitable strategy.
정답:
Explanation:
When prioritizing cost and latency over quality in a Large Language Model (LLM)-based application, it is crucial to select a configuration that minimizes both computational resources and latency while still providing reasonable performance.
Here's why D is the best choice:
Context length: The context length of 512 tokens aligns with the chunk size used for the documents (maximum of 512 tokens per chunk). This is sufficient for capturing the needed information and generating responses without unnecessary overhead.
Smallest model size: The model with a size of 0.13GB is significantly smaller than the other options. This small footprint ensures faster inference times and lower memory usage, which directly reduces both latency and cost.
Embedding dimension: While the embedding dimension of 384 is smaller than the other options, it is still adequate for tasks where cost and speed are more important than precision and depth of understanding.
This setup achieves the desired balance between cost-efficiency and reasonable performance in a latency-sensitive, cost-conscious application.
정답:
Explanation:
Addressing offensive or inflammatory outputs in a Retrieval-Augmented Generation (RAG) system is critical for improving user experience and ensuring ethical AI deployment.
Here's why D is the most effective approach:
Manual data curation: The root cause of offensive outputs often comes from the underlying data used to train the model or populate the retrieval system. By manually curating the upstream data and conducting thorough reviews before the data is fed into the RAG system, the engineer can filter out harmful, offensive, or inappropriate content.
Improving data quality: Curating data ensures the system retrieves and generates responses from a high-quality, well-vetted dataset. This directly impacts the relevance and appropriateness of the outputs from the RAG system, preventing inflammatory content from being included in responses. Effectiveness: This strategy directly tackles the problem at its source (the data) rather than just mitigating the consequences (such as informing users or restricting access). It ensures that the system consistently provides non-offensive, relevant information.
Other options, such as increasing the frequency of data updates or informing users about behavior expectations, may not directly mitigate the generation of inflammatory outputs.
정답:
Explanation:
Problem Context: The goal is to monitor the serving endpoint for incoming requests and outgoing responses in a provisioned throughput model serving endpoint within a Retrieval-Augmented Generation (RAG) application. The current approach involves using a microservice to log requests and responses to a remote server, but the Generative AI Engineer is looking for a more streamlined solution within Databricks.
Explanation of Options:
Option A: Vector Search: This feature is used to perform similarity searches within vector databases. It doesn’t provide functionality for logging or monitoring requests and responses in a serving endpoint, so it’s not applicable here.
Option B: Lakeview: Lakeview is not a feature relevant to monitoring or logging request-response cycles for serving endpoints. It might be more related to viewing data in Databricks Lakehouse but doesn’t fulfill the specific monitoring requirement.
Option C: DBSQL: Databricks SQL (DBSQL) is used for running SQL queries on data stored in
Databricks, primarily for analytics purposes. It doesn’t provide the direct functionality needed to monitor requests and responses in real-time for an inference endpoint.
Option D: Inference Tables: This is the correct answer. Inference Tables in Databricks are designed to store the results and metadata of inference runs. This allows the system to log incoming requests and outgoing responses directly within Databricks, making it an ideal choice for monitoring the behavior of a provisioned serving endpoint. Inference Tables can be queried and analyzed, enabling easier monitoring and debugging compared to a custom microservice.
Thus, Inference Tables are the optimal feature for monitoring request and response logs within the Databricks infrastructure for a model serving endpoint.