
매달, 우리는 1000명 이상의 사람들이 시험 준비를 잘하고 시험을 잘 통과할 수 있도록 도와줍니다.
Databricks Certified Data Analyst Associate Exam 온라인 연습
최종 업데이트 시간: 2025년10월10일
당신은 온라인 연습 문제를 통해 Databricks Databricks Certified Data Analyst Associate 시험지식에 대해 자신이 어떻게 알고 있는지 파악한 후 시험 참가 신청 여부를 결정할 수 있다.
시험을 100% 합격하고 시험 준비 시간을 35% 절약하기를 바라며 Databricks Certified Data Analyst Associate 덤프 (최신 실제 시험 문제)를 사용 선택하여 현재 최신 45개의 시험 문제와 답을 포함하십시오.

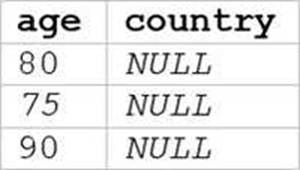
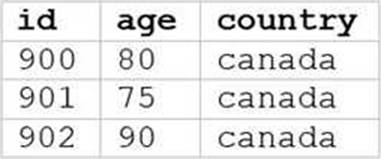
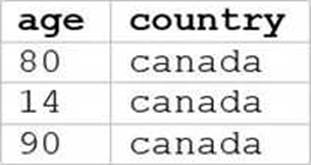
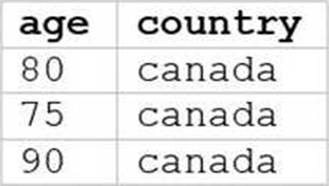
정답:
Explanation:
The SQL query provided is designed to filter out records from “my_table” where the age is 75 or above and the country is Canada. Since I can’t view the content of the links provided directly, I need to rely on the image attached to this question for context. Based on that, Option E (the image attached) represents a table with columns “age” and “country”, showing records where age is 75 or above and country is Canada.
Reference: The answer can be inferred from understanding SQL queries and their outputs as per Databricks documentation: Databricks SQL
정답:
Explanation:
The DROP TABLE command removes a table from the metastore and deletes the associated data files. The syntax for this command is DROP TABLE [IF EXISTS] [database_name.]table_name;. The optional IF EXISTS clause prevents an error if the table does not exist. The optional database_name. prefix specifies the database where the table resides. If not specified, the current database is used. Therefore, the correct command to remove the table table_name from the database database_name and all of the data files associated with it is DROP TABLE database_name.table_name;. The other commands are either invalid syntax or would produce undesired results.
Reference: Databricks - DROP TABLE
정답:
Explanation:
The Owner field in the table page shows the current owner of the table and allows the owner to change it to another user or group. To change the ownership of the table, the owner can click on the Owner field and select the new owner from the drop-down list. This will transfer the ownership of the table to the selected user or group and remove the previous owner from the list of table access control entries1.
The other options are incorrect because:
A. Removing the owner’s account from the Owner field will not change the ownership of the table, but will make the table ownerless2.
B. Selecting All Users from the Owner field will not change the ownership of the table, but will grant all users access to the table3.
D. Selecting the Admins group from the Owner field will not change the ownership of the table, but will grant the Admins group access to the table3.
E. Removing all access from the Owner field will not change the ownership of the table, but will revoke all access to the table4.
Reference: 1: Change table ownership
2: Ownerless tables
3: Table access control
4: Revoke access to a table

정답:
Explanation:
In Databricks, a view is a saved SQL query definition that references existing tables or other views.
Once created, a view remains persisted in the metastore (such as Unity Catalog or Hive Metastore) until it is explicitly dropped.
Key points:
Views do not store data themselves but reference data from underlying tables.
Logging out or being inactive does not delete or alter views.
Unless a user or admin explicitly drops the view or the underlying data/table is deleted, the view continues to function as expected.
Therefore, after logging back in―even days later―a user can still run SELECT * FROM stakeholders.eur_customers, and it will return the same data (provided the underlying table hasn’t changed).
Reference: Views - Databricks Documentation
정답:
Explanation:
Data Explorer is a user interface that allows you to discover and manage data, schemas, tables, models, and permissions in Databricks SQL. You can use Data Explorer to view schema details, preview sample data, and see table and model details and properties. Administrators can view and change owners, and admins and data object owners can grant and revoke
permissions1.
Reference: Discover and manage data using Data Explorer
정답:
Explanation:
A Delta Lake-based data lakehouse is a data platform architecture that combines the scalability and flexibility of a data lake with the reliability and performance of a data warehouse. One of the key advantages of using a Delta Lake-based data lakehouse over common data lake solutions is that it supports ACID transactions, which ensure data integrity and consistency. ACID transactions enable concurrent reads and writes, schema enforcement and evolution, data versioning and rollback, and data quality checks. These features are not available in traditional data lakes, which rely on file-based storage systems that do not support transactions.
Reference: Delta Lake: Lakehouse, warehouse, advantages | Definition Synapse C Data Lake vs. Delta Lake vs. Data Lakehouse Data Lake vs. Delta Lake - A Detailed Comparison
Building a Data Lakehouse with Delta Lake Architecture: A Comprehensive Guide
정답:
Explanation:
Delta Lake is a storage layer that enhances data lakes with features like ACID transactions, schema enforcement, and time travel. While it stores table data as Parquet files, Delta Lake also keeps a transaction log (stored in the _delta_log directory) that contains detailed table metadata.
This metadata includes:
Table schema
Partitioning information
Data file paths
Transactional operations like inserts, updates, and deletes
Commit history and version control
This metadata is critical for supporting Delta Lake’s advanced capabilities such as time travel and efficient query execution. Delta Lake does not store data summary visualizations or owner account information directly alongside the data files.
Reference: Delta Lake Table Features - Databricks Documentation
정답:
Explanation:
Data analysts should consider all of these factors when working with PII data, as they may affect the data security, privacy, compliance, and quality. PII data is any information that can be used to identify a specific individual, such as name, address, phone number, email, social security number, etc. PII data may be subject to different legal and ethical obligations depending on the context and location of the data collection and analysis. For example, some countries or regions may have stricter data protection laws than others, such as the General Data Protection Regulation (GDPR) in the European Union. Data analysts should also follow the organization-specific best practices for PII data, such as encryption, anonymization, masking, access control, auditing, etc. These best practices can help prevent data breaches, unauthorized access, misuse, or loss of PII data.
Reference: How to Use Databricks to Encrypt and Protect PII Data
Automating Sensitive Data (PII/PHI) Detection
Databricks Certified Data Analyst Associate

정답:
Explanation:
the accounts.customers table is an EXTERNAL table, which means that it is stored outside the default warehouse directory and is not managed by Databricks. Therefore, when you run the DROP command on this table, it only removes the metadata information from the metastore, but does not delete the actual data files from the file system. This means that you can still access the data using the location path (dbfs:/stakeholders/customers) or create another table pointing to the same location. However, if you try to query the table using its name (accounts.customers), you will get an error because the table no longer exists in the metastore.
Reference: DROP TABLE | Databricks on AWS, Best practices for dropping a managed Delta Lake table - Databricks
정답:
Explanation:
An external table is a table that is defined in the metastore, but its data is stored outside of the Databricks environment, such as in S3, ADLS, or GCS. When an external table is dropped, only the metadata is deleted from the metastore, but the data files are not affected. This is different from a managed table, which is a table whose data is stored in the Databricks environment, and whose data files are deleted when the table is dropped. To delete the data files of an external table, the analyst needs to specify the PURGE option in the DROP TABLE command, or manually delete the files from the storage system.
Reference: DROP TABLE, Drop Delta table features, Best practices for dropping a managed Delta Lake table
정답:
Explanation:
Databricks SQL is a serverless data warehouse on the Lakehouse that lets you run all of your SQL and BI applications at scale with your tools of choice, all at a fraction of the cost of traditional cloud data warehouses1. Databricks SQL allows you to create SQL queries and data visualizations using the SQL Analytics UI or the Databricks SQL CLI2. You can also place your data visualizations within a dashboard and share it with other users in your organization3. Databricks SQL is powered by Delta Lake, which provides reliability, performance, and governance for your data lake4.
Reference: Databricks SQL
Query data using SQL Analytics
Visualizations in Databricks notebooks
Delta Lake
정답:
Explanation:
Markdown-based text boxes are useful as labels on a dashboard. They allow the data analyst to add text to a dashboard using the %md magic command in a notebook cell and then select the dashboard icon in the cell actions menu. The text can be formatted using markdown syntax and can include headings, lists, links, images, and more. The text boxes can be resized and moved around on the dashboard using the float layout option.
Reference: Dashboards in notebooks, How to add text to a dashboard in Databricks
정답:
Explanation:
External tables are tables that are defined in the Databricks metastore using the information stored in a cloud object storage location. External tables do not manage the data, but provide a schema and a table name to query the data. To create an external table, you can use the CREATE EXTERNAL TABLE statement and specify the object storage path to the LOCATION clause. For example, to create an external table named ext_table on a Parquet file stored in S3, you can use the following statement: SQL
CREATE EXTERNAL TABLE ext_table (
col1 INT,
col2 STRING
)
STORED AS PARQUET
LOCATION 's3://bucket/path/file.parquet'
AI-generated code. Review and use carefully. More info on FAQ.
Reference: External tables
정답:
Explanation:
A Structured Streaming pipeline that processes data in micro-batches and populates gold-level tables every minute requires a high level of compute resources to handle the frequent data ingestion, processing, and writing. This could result in a significant cost for the organization, especially if the data volume and velocity are large. Therefore, the data analyst should share this caution with the project stakeholders before setting up the dashboard and evaluate the trade-offs between the desired refresh rate and the available budget.
The other options are not valid cautions because:
B. The gold-level tables are assumed to be appropriately clean for business reporting, as they are the final output of the data engineering pipeline. If the data quality is not satisfactory, the issue should be addressed at the source or silver level, not at the gold level.
C. The streaming data is an appropriate data source for a dashboard, as it can provide near real-time insights and analytics for the business users. Structured Streaming supports various sources and sinks for streaming data, including Delta Lake, which can enable both batch and streaming queries on the same data.
D. The streaming cluster is fault tolerant, as Structured Streaming provides end-to-end exactly-once fault-tolerance guarantees through checkpointing and write-ahead logs. If a query fails, it can be restarted from the last checkpoint and resume processing.
E. The dashboard can be refreshed within one minute or less of new data becoming available in the gold-level tables, as Structured Streaming can trigger micro-batches as fast as possible (every few seconds) and update the results incrementally. However, this may not be necessary or optimal for the business use case, as it could cause frequent changes in the dashboard and consume more resources.
Reference: Streaming on Databricks, Monitoring Structured Streaming queries on Databricks, A look at the new Structured Streaming UI in Apache Spark 3.0, Run your first Structured Streaming workload
정답:
Explanation:
A Serverless SQL endpoint is a type of SQL endpoint that does not require a dedicated cluster to run queries. Instead, it uses a shared pool of resources that can scale up and down automatically based on the demand. This means that a Serverless SQL endpoint can start up much faster than a SQL
endpoint that uses a cluster, and it can also save costs by only paying for the resources that are used. A Serverless SQL endpoint is suitable for ad-hoc queries and exploratory analysis, but it may not offer the same level of performance and isolation as a SQL endpoint that uses a cluster. Therefore, a data analyst should consider the trade-offs between speed, cost, and quality when choosing between a Serverless SQL endpoint and a SQL endpoint that uses a cluster.
Reference: Databricks SQL endpoints, Serverless SQL endpoints, SQL endpoint clusters