당신은 온라인 연습 문제를 통해 Microsoft DP-201 시험지식에 대해 자신이 어떻게 알고 있는지 파악한 후 시험 참가 신청 여부를 결정할 수 있다.
시험을 100% 합격하고 시험 준비 시간을 35% 절약하기를 바라며 DP-201 덤프 (최신 실제 시험 문제)를 사용 선택하여 현재 최신 141개의 시험 문제와 답을 포함하십시오.
/ 4
Question No : 1
A company is developing a mission-critical line of business app that uses Azure SQL Database Managed Instance. You must design a disaster recovery strategy for the solution.
You need to ensure that the database automatically recovers when full or partial loss of the Azure SQL Database service occurs in the primary region.
What should you recommend?
정답: Explanation:
Auto-failover groups is a SQL Database feature that allows you to manage replication and failover of a group of databases on a SQL Database server or all databases in a Managed Instance to another region (currently in public preview for Managed Instance). It uses the same underlying technology as active geo-replication. You can initiate failover manually or you can delegate it to the SQL Database service based on a user-defined policy.
References: https://docs.microsoft.com/en-us/azure/sql-database/sql-database-auto-failover-group
Question No : 2
HOTSPOT
A company stores large datasets in Azure, including sales transactions and customer account information.
You must design a solution to analyze the data.
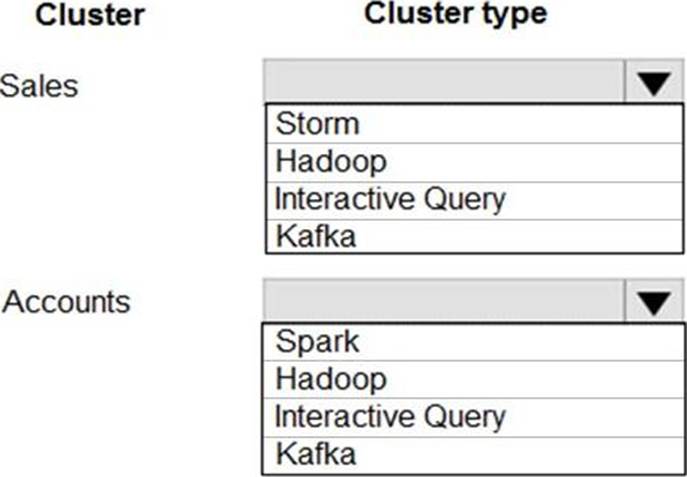
You plan to create the following HDInsight clusters:
You need to ensure that the clusters support the query requirements.
Which cluster types should you recocmmend? To answer, select the appropriate configuration in the answer area. NOTE: Each correct seletion is worth one point.
정답:
Explanation:
Box 1: Interactive Query
Choose Interactive Query cluster type to optimize for ad hoc, interactive queries.
Box 2: Hadoop
Choose Apache Hadoop cluster type to optimize for Hive queries used as a batch process.
Note: In Azure HDInsight, there are several cluster types and technologies that can run Apache Hive queries. When you create your HDInsight cluster, choose the appropriate cluster type to help optimize performance for your workload needs.
For example, choose Interactive Query cluster type to optimize for ad hoc, interactive queries. Choose Apache Hadoop cluster type to optimize for Hive queries used as a batch process. Spark and HBase cluster types can also run Hive queries.
References: https://docs.microsoft.com/bs-latn-ba/azure/hdinsight/hdinsight-hadoop-optimize-hive-query?toc=%2Fko-kr%2Fazure%2Fhdinsight%2Finteractive-query%2FTOC.json&bc=%2Fbs-latn-ba%2Fazure%2Fbread%2Ftoc.json
Question No : 3
HOTSPOT
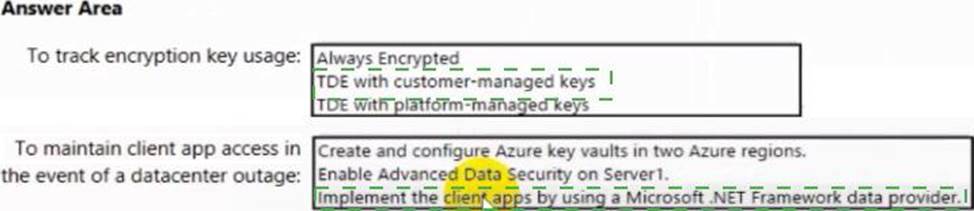
You have an Azure subscription that contains a logical Microsoft SQL server named Server1. Server1 hosts an Azure Synapse Analytics SQL dedicated pool named Pool1. You need to recommend a Transparent Data Encryption (TDE) solution for Server1.
The solution must meet the following requirements:
• Track the usage of encryption keys.
• Maintain the access of client apps to Pool1 in the event of an Azure datacenter outage
that affects the availability of the encryption keys.
What should you include in the recommendation? To answer, select the appropriate options in the answer area.
정답:
Question No : 4
HOTSPOT
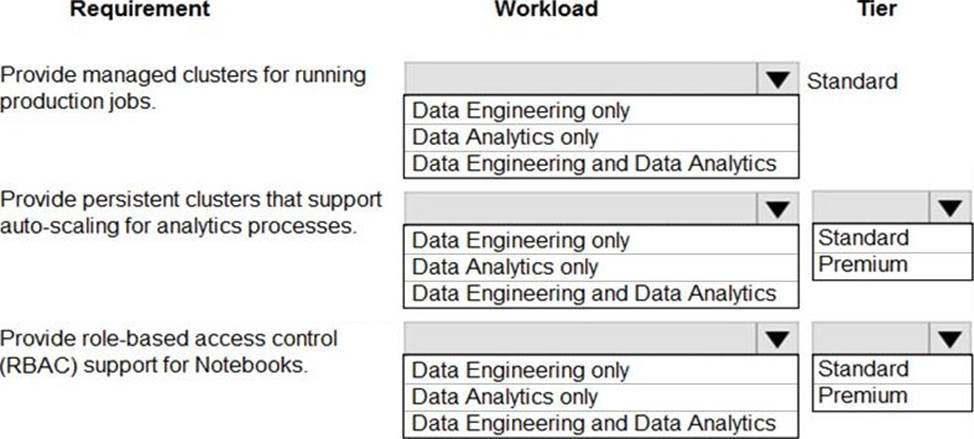
You are designing a solution for a company. You plan to use Azure Databricks.
You need to recommend workloads and tiers to meet the following requirements:
✑ Provide managed clusters for running production jobs.
✑ Provide persistent clusters that support auto-scaling for analytics processes.
✑ Provide role-based access control (RBAC) support for Notebooks.
What should you recommend? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.
정답:
Explanation:
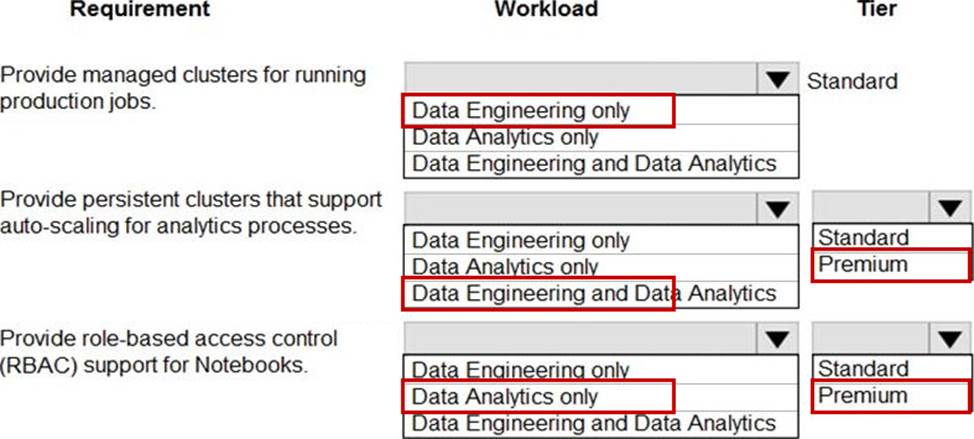
Box 1: Data Engineering Only
Box 2: Data Engineering and Data Analytics
Box 3: Standard
Box 4: Data Analytics only
Box 5: Premium
Premium required for RBAC. Data Analytics Premium Tier provide interactive workloads to analyze data collaboratively with notebooks
References: https://azure.microsoft.com/en-us/pricing/details/databricks/
Question No : 5
HOTSPOT
You have an Azure Data Lake Storage Gen2 account named account1 that stores logs as shown in the following table.
You do not expect that the logs will be accessed during the retention periods.
You need to recommend a solution for account1 that meets the following requirements:
✑ Automatically deletes the logs at the end of each retention period
✑ Minimizes storage costs
What should you include in the recommendation? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.
정답:
Explanation:
Box 1: Store the infrastructure in the Cool access tier and the application logs in the Archive access tier.
Cool - Optimized for storing data that is infrequently accessed and stored for at least 30 days.
Archive - Optimized for storing data that is rarely accessed and stored for at least 180 days with flexible latency requirements, on the order of hours.
Box 2: Azure Blob storage lifecycle management rules
Blob storage lifecycle management offers a rich, rule-based policy that you can use to transition your data to the best access tier and to expire data at the end of its lifecycle.
Question No : 6
You plan to create an Azure Synapse Analytics dedicated SQL pool.
You need to minimize the time it takes to identify queries that return confidential information as defined by the company’s data privacy regulations and the users who executed the queries.
Which two components should you include in the solution? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
You are designing a statistical analysis solution that will use custom proprietary Python functions on near real-time data from Azure Event Hubs.
You need to recommend which Azure service to use to perform the statistical analysis. The solution must minimize latency.
What should you recommend?
HOTSPOT
You manage an on-premises server named Server1 that has a database named Database1. The company purchases a new application that can access data from Azure SQL Database.
You recommend a solution to migrate Database1 to an Azure SQL Database instance.
What should you recommend? To answer, select the appropriate configuration in the answer area. NOTE: Each correct selection is worth one point.
HOTSPOT
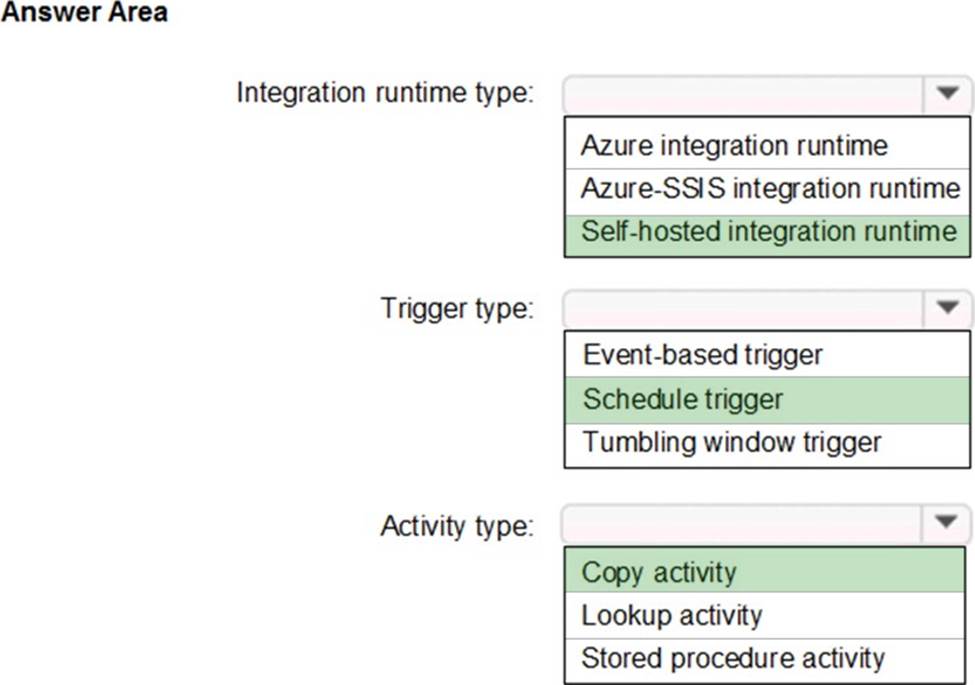
Which Azure Data Factory components should you recommend using together to import the daily inventory data from SQL to Data Lake Storage? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.
정답:
Explanation:
Box 1: Self-hosted integration runtime
A self-hosted IR is capable of nunning copy activity between a cloud data stores and a data store in private network.
Scenario: Daily inventory data comes from a Microsoft SQL server located on a private network.
Box 2: Schedule trigger
Daily schedule
Box 3: Copy activity
Scenario:
Stage inventory data in Azure Data Lake Storage Gen2 before loading the data into the analytical data store. Litware wants to remove transient data from Data Lake Storage once the data is no longer in use. Files that have a modified date that is older than 14 days must be removed.
Question No : 10
HOTSPOT
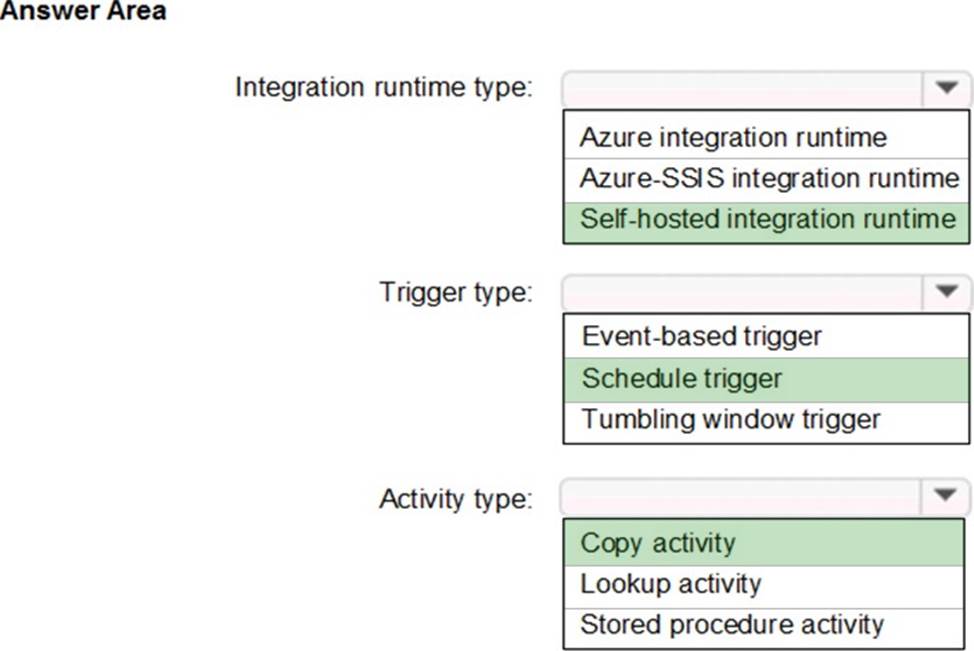
Which Azure Data Factory components should you recommend using together to import the customer data from Salesforce to Data Lake Storage? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.
정답:
Explanation:
Box 1: Self-hosted integration runtime
A self-hosted IR is capable of nunning copy activity between a cloud data stores and a data
store in private network.
Box 2: Schedule trigger
Schedule every 8 hours
Box 3: Copy activity
Scenario:
✑ Customer data, including name, contact information, and loyalty number, comes from Salesforce and can be imported into Azure once every eight hours. Row modified dates are not trusted in the source table.
✑ Product data, including product ID, name, and category, comes from Salesforce and can be imported into Azure once every eight hours. Row modified dates are not trusted in the source table.
Question No : 11
Which Azure service should you recommend for the analytical data store so that the business analysts and data scientists can execute ad hoc queries as quickly as possible?
정답: Explanation:
There are several differences between a data lake and a data warehouse. Data structure, ideal users, processing methods, and the overall purpose of the data are the key differentiators.
Scenario: Litware employs business analysts who prefer to analyze data by using Microsoft Power BI, and data scientists who prefer analyzing data in Azure Databricks notebooks.
Question No : 12
HOTSPOT
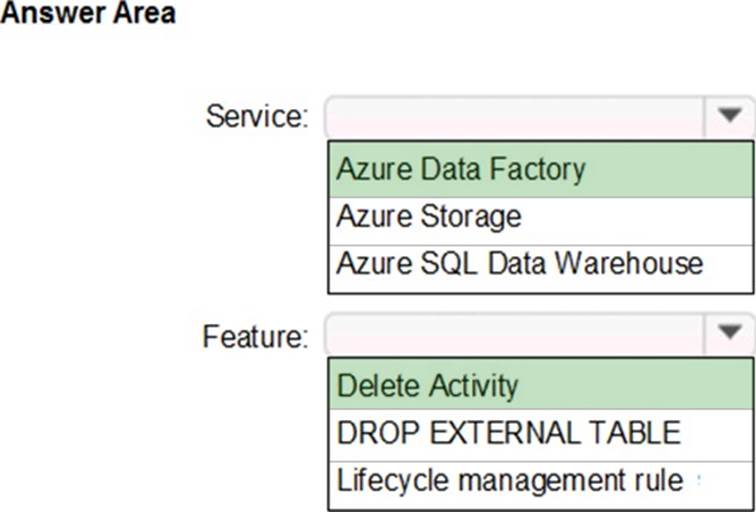
Which Azure service and feature should you recommend using to manage the transient data for Data Lake Storage? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.
정답:
Explanation:
Scenario: Stage inventory data in Azure Data Lake Storage Gen2 before loading the data into the analytical data store. Litware wants to remove transient data from Data Lake Storage once the data is no longer in use. Files that have a modified date that is older than 14 days must be removed.
Service: Azure Data Factory
Clean up files by built-in delete activity in Azure Data Factory (ADF).
ADF built-in delete activity, which can be part of your ETL workflow to deletes undesired files without writing code. You can use ADF to delete folder or files from Azure Blob Storage, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2, File System, FTP Server, sFTP Server, and Amazon S3.
You can delete expired files only rather than deleting all the files in one folder. For example, you may want to only delete the files which were last modified more than 13 days ago.
Feature: Delete Activity
Question No : 13
Inventory levels must be calculated by subtracting the current day's sales from the previous day's final inventory.
Which two options provide Litware with the ability to quickly calculate the current inventory levels by store and product? Each correct answer presents a complete solution. NOTE: Each correct selection is worth one point.
정답: Explanation:
A: Azure Stream Analytics is a fully managed service providing low-latency, highly available, scalable complex event processing over streaming data in the cloud. You can use your Azure SQL Data Warehouse database as an output sink for your Stream Analytics jobs.
E: Event Hubs Capture is the easiest way to get data into Azure. Using Azure Data Lake, Azure Data Factory, and Azure HDInsight, you can perform batch processing and other analytics using familiar tools and platforms of your choosing, at any scale you need.
Note: Event Hubs Capture creates files in Avro format.
Captured data is written in Apache Avro format: a compact, fast, binary format that provides rich data structures with inline schema. This format is widely used in the Hadoop ecosystem, Stream Analytics, and Azure Data Factory.
Scenario: The application development team will create an Azure event hub to receive real-time sales data, including store number, date, time, product ID, customer loyalty number, price, and discount amount, from the point of sale (POS) system and output the data to data storage in Azure.
Reference:
https://docs.microsoft.com/bs-latn-ba/azure/sql-data-warehouse/sql-data-warehouse-integrate-azurestream-analytics
https://docs.microsoft.com/en-us/azure/event-hubs/event-hubs-capture-overview
Question No : 14
Topic 6, Litware Case
Case study
This is a case study. Case studies are not timed separately. You can use as much exam time as you would like to complete each case. However, there may be additional case studies and sections on this exam. You must manage your time to ensure that you are able to complete all questions included on this exam in the time provided.
To answer the questions included in a case study, you will need to reference information that is provided in the case study. Case studies might contain exhibits and other resources that provide more information about the scenario that is described in the case study. Each question is independent of the other questions in this case study.
At the end of this case study, a review screen will appear. This screen allows you to review your answers and to make changes before you move to the next section of the exam. After you begin a new section, you cannot return to this section.
To start the case study
To display the first question in this case study, click the Next button. Use the buttons in the left pane to explore the content of the case study before you answer the questions. Clicking these buttons displays information such as business requirements, existing environment, and problem statements. If the case study has an All Information tab, note that the information displayed is identical to the information displayed on the subsequent tabs. When you are ready to answer a question, click the Question button to return to the question.
Overview
Litware, Inc. owns and operates 300 convenience stores across the US. The company sells a variety of packaged foods and drinks, as well as a variety of prepared foods, such as sandwiches and pizzas.
Litware has a loyalty club whereby members can get daily discounts on specific items by providing their membership number at checkout.
Litware employs business analysts who prefer to analyze data by using Microsoft Power BI, and data scientists who prefer analyzing data in Azure Databricks notebooks.
Requirements. Business Goals
Litware wants to create a new analytics environment in Azure to meet the following requirements:
- See inventory levels across the stores. Data must be updated as close to real time as possible.
- Execute ad hoc analytical queries on historical data to identify whether the loyalty club discounts increase sales of the discounted products.
- Every four hours, notify store employees about how many prepared food items to produce based on historical demand from the sales data.
Requirements. Technical Requirements
Litware identifies the following technical requirements:
- Minimize the number of different Azure services needed to achieve the business goals
- Use platform as a service (PaaS) offerings whenever possible and avoid having to provision virtual machines that must be managed by Litware.
- Ensure that the analytical data store is accessible only to the company’s on-premises network and Azure services.
- Use Azure Active Directory (Azure AD) authentication whenever possible.
- Use the principle of least privilege when designing security.
- Stage inventory data in Azure Data Lake Storage Gen2 before loading the data into the analytical data store. Litware wants to remove transient data from Data Lake Storage once the data is no longer in use. Files that have a modified date that is older than 14 days must be removed.
- Limit the business analysts’ access to customer contact information, such as phone numbers, because this type of data is not analytically relevant.
- Ensure that you can quickly restore a copy of the analytical data store within one hour in the event of corruption or accidental deletion.
Requirements. Planned Environment
Litware plans to implement the following environment:
- The application development team will create an Azure event hub to receive real-time sales data, including store number, date, time, product ID, customer loyalty number, price, and discount amount, from the point of sale (POS) system and output the data to data storage in Azure.
- Customer data, including name, contact information, and loyalty number, comes from Salesforce and can be imported into Azure once every eight hours. Row modified dates are not trusted in the source table.
- Product data, including product ID, name, and category, comes from Salesforce and can be imported into Azure once every eight hours. Row modified dates are not trusted in the source table.
- Daily inventory data comes from a Microsoft SQL server located on a private network.
- Litware currently has 5 TB of historical sales data and 100 GB of customer data. The company expects approximately 100 GB of new data per month for the next year.
- Litware will build a custom application named FoodPrep to provide store employees with the calculation results of how many prepared food items to produce every four hours.
- Litware does not plan to implement Azure ExpressRoute or a VPN between the on-premises network and Azure.
What should you do to improve high availability of the real-time data processing solution?
정답: Explanation:
Guarantee Stream Analytics job reliability during service updates
Part of being a fully managed service is the capability to introduce new service functionality and improvements at a rapid pace. As a result, Stream Analytics can have a service update deploy on a weekly (or more frequent) basis. No matter how much testing is done there is still a risk that an existing, running job may break due to the introduction of a bug. If you are running mission critical jobs, these risks need to be avoided. You can reduce this risk by following Azure’s paired region model.
Scenario: The application development team will create an Azure event hub to receive real-time sales data, including store number, date, time, product ID, customer loyalty number, price, and discount amount, from the point of sale (POS) system and output the data to data storage in Azure
Reference: https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-job-reliability
Question No : 15
You need to design the solution for the government planning department.
Which services should you include in the design?
정답: Explanation:
PolyBase is a new feature in SQL Server 2016. It is used to query relational and non-relational databases (NoSQL) such as CSV files.
Scenario: Traffic data must be made available to the Government Planning Department for the purpose of modeling changes to the highway system. The traffic data will be used in conjunction with other data such as information about events such as sporting events, weather conditions, and population statistics. External data used during the modeling is stored in on-premises SQL Server 2016 databases and CSV files stored in an Azure Data Lake Storage Gen2 storage account.
Reference: https://www.sqlshack.com/sql-server-2016-polybase-tutorial/