
매달, 우리는 1000명 이상의 사람들이 시험 준비를 잘하고 시험을 잘 통과할 수 있도록 도와줍니다.
CertNexus Certified Artificial Intelligence Practitioner (CAIP) 온라인 연습
최종 업데이트 시간: 2025년11월17일
당신은 온라인 연습 문제를 통해 CertNexus AIP-210 시험지식에 대해 자신이 어떻게 알고 있는지 파악한 후 시험 참가 신청 여부를 결정할 수 있다.
시험을 100% 합격하고 시험 준비 시간을 35% 절약하기를 바라며 AIP-210 덤프 (최신 실제 시험 문제)를 사용 선택하여 현재 최신 90개의 시험 문제와 답을 포함하십시오.
정답:
Explanation:
Underfitting is a problem that occurs when a model learns too little from the training data and fails to capture the underlying complexity or structure of the data. Underfitting can result from using insufficient or irrelevant features, a low complexity of the model, or a lack of training data. Underfitting can reduce the accuracy and generalization of the model, as it may produce oversimplified or inaccurate predictions.
Some of the ways to fix underfitting are:
Add features to training data: Adding more features or variables to the training data can help increase the information and diversity of the data, which can help the model learn more complex patterns and relationships.
Increase the complexity of the model: Increasing the complexity of the model can help increase its expressive power and flexibility, which can help it fit better to the data. For example, adding more layers or nodes to a neural network can increase its complexity.
Train the model for more epochs: Training the model for more epochs can help increase its learning ability and convergence, which can help it optimize its parameters and reduce its error.
Getting more training data will not work to fix underfitting, as it will not change the complexity or structure of the data or the model. Getting more training data may help with overfitting, which is when a model learns too much from the training data and fails to generalize well to new or unseen data.
정답:
Explanation:
Emergent bias is a type of bias that arises when an AI model encounters new or different data or scenarios that were not present or accounted for during its training or development. Emergent bias can cause the model to make inaccurate or unfair predictions or decisions, as it may not be able to generalize well to new situations or adapt to changing conditions. One possible cause of emergent bias is seasonality, which means that some variables or patterns in the data may vary depending on the time of year. For example, if an AI model for merchandise sales prediction was trained in winter and applied in summer, it may produce biased results due to differences in customer behavior, demand, or preferences.
정답:
Explanation:
Hidden attacks are malicious activities that aim to compromise or manipulate an ML system without being detected or noticed. Hidden attacks can target different stages of an ML workflow, such as data collection, model training, model deployment, or model monitoring. Some examples of hidden attacks are data poisoning, backdoor attacks, model stealing, or adversarial examples. Continuous monitoring of bias and variance can help ML engineers to prevent hidden attacks, as it can help them detect any anomalies or deviations in the data or the model’s performance that may indicate a potential attack.
정답:
Explanation:
Missing values are a common problem in data analysis and machine learning, as they can affect the quality and reliability of the data and the model. There are various methods to deal with missing values, such as deleting, imputing, or ignoring them. One of the most common methods is imputing, which means replacing the missing values with some estimated values based on some criteria. For continuous variables, one of the simplest and most widely used imputation methods is to fill in the missing values with the mean (average) of the observed values for that variable in the entire dataset. This method can preserve the overall distribution and variance of the data, as well as avoid introducing bias or noise.
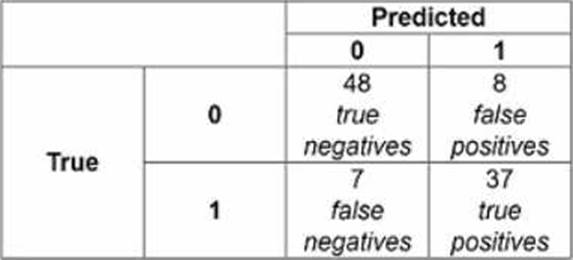
정답:
Explanation:
Precision is a measure of how well a classifier can avoid false positives (incorrectly predicted positive cases). Precision is calculated by dividing the number of true positives (correctly predicted positive cases) by the number of predicted positive cases (true positives and false positives). In this confusion matrix, the true positives are 37 and the false positives are 8, so the precision is 37/(37+8) = 0.822.
정답:
Explanation:
A neural network without an activation function is equivalent to a form of a linear regression. A neural network is a computational model that consists of layers of interconnected nodes (neurons) that process inputs and produce outputs. An activation function is a function that determines the output of a neuron based on its input. An activation function can introduce non-linearity into a neural network, which allows it to model complex and non-linear relationships between inputs and outputs. Without an activation function, a neural network becomes a linear combination of inputs and weights, which is essentially a linear regression model.
정답:
Explanation:
Technical debt is a metaphor that describes the implied cost of additional work or rework caused by choosing an easy or quick solution over a better but more complex solution. Technical debt can accumulate in ML systems due to various factors, such as changing requirements, outdated code, poor documentation, or lack of testing.
Some of the ways to decrease technical debt in ML systems are:
Documentation readability: Documentation readability refers to how easy it is to understand and use the documentation of an ML system. Documentation readability can help reduce technical debt by providing clear and consistent information about the system’s design, functionality, performance, and maintenance. Documentation readability can also facilitate communication and collaboration among different stakeholders, such as developers, testers, users, and managers.
Refactoring: Refactoring is the process of improving the structure and quality of code without changing its functionality. Refactoring can help reduce technical debt by eliminating code smells, such as duplication, complexity, or inconsistency. Refactoring can also enhance the readability, maintainability, and extensibility of code.
정답:
Explanation:
Highly interpretable models are models that can provide clear and intuitive explanations for their predictions, such as decision trees, linear regression, or logistic regression.
Some of the statements that are true regarding highly interpretable models are:
They are usually easier to explain to business stakeholders: Highly interpretable models can help communicate the logic and reasoning behind their predictions, which can increase trust and confidence among business stakeholders. For example, a decision tree can show how each feature contributes to a decision outcome, or a linear regression can show how each coefficient affects the dependent variable.
They usually compromise on model accuracy for the sake of interpretability: Highly interpretable models may not be able to capture complex or non-linear patterns in the data, which can reduce their accuracy and generalization. For example, a decision tree may overfit or underfit the data if it is too deep or too shallow, or a linear regression may not be able to model curved relationships between variables.
정답:
Explanation:
An L1 norm is a measure of distance or magnitude that is defined as the sum of the absolute values of the components of a vector. For example, if x and y are two components of a vector, then the L1 norm of that vector is |x| + |y|. The L1 norm is also known as the Manhattan distance or the taxicab distance, as it represents the shortest path between two points in a grid-like city.
정답:
Explanation:
R-squared is a statistical measure that indicates how well a regression model fits the data. R-squared is calculated by dividing the explained variance by the total variance. The explained variance is the amount of variation in the dependent variable that can be attributed to the independent variables. The total variance is the amount of variation in the dependent variable that can be observed in the data. R-squared ranges from 0 to 1, where 0 means no fit and 1 means perfect fit.
정답:
Explanation:
Reinforcement learning is a type of machine learning that involves learning from trial and error based on rewards and penalties. Reinforcement learning can be used to develop models for dynamic pathing, which is the problem of finding an optimal path from one point to another in an uncertain and changing environment. Reinforcement learning can enable the model to adapt to new situations and learn from its own actions and feedback. For example, a self-driving car company can use reinforcement learning to train its model to navigate complex traffic scenarios and avoid collisions.
정답:
Explanation:
Cloud models are service models that provide different levels of abstraction and control over computing resources in a cloud environment. Some of the common cloud models for machine learning pipelines are:
Software as a Service (SaaS): SaaS provides ready-to-use applications that run on the cloud provider’s infrastructure and are accessible through a web browser or an API. SaaS can provide AI practitioner data science services such as Jupyter notebooks, which are web-based interactive environments that allow users to create and share documents that contain code, text, visualizations, and more.
Platform as a Service (PaaS): PaaS provides a platform that allows users to develop, run, and manage applications without worrying about the underlying infrastructure. PaaS can provide some services within an application such as payment applications to create efficient results.
Infrastructure as a Service (IaaS): IaaS provides access to fundamental computing resources such as servers, storage, networks, and operating systems. IaaS can provide CPU, memory, disk, network and GPU resources that can be used to run machine learning models and applications.
Data as a Service (DaaS): DaaS provides access to data sources that can be consumed by applications or users on demand. DaaS can host the databases providing backups, clustering, and high availability.
정답:
Explanation:
Personal data is any information that relates to an identified or identifiable individual, such as name, address, email, phone number, or biometric data. Personal data should not be disclosed, made available, or otherwise used for purposes other than specified, except with:
The consent of the person it is collected from: Consent is a clear and voluntary indication of agreement by the person to the processing of their personal data for a specific purpose. Consent can be given by a statement or a clear affirmative action, such as ticking a box or clicking a button.
The authority of law: The authority of law is a legal basis or obligation that requires or permits the processing of personal data for a legitimate purpose. For example, the authority of law could be a court order, a subpoena, a warrant, or a statute.
정답:
Explanation:
Accuracy is a measure of how well a classifier can correctly predict the class of an instance. Accuracy is calculated by dividing the number of correct predictions (true positives and true negatives) by the total number of predictions. True positives are instances that are correctly predicted as positive (belonging to the target class). True negatives are instances that are correctly predicted as negative (not belonging to the target class).
정답:
Explanation:
Latency is the time delay between a request and a response. Latency can affect the performance and user experience of an application, especially when real-time or near-real-time responses are required. Deploying a deep learning model as an embedded model on edge devices can reduce latency, as the model can run locally on the device without relying on network connectivity or cloud servers. Edge devices are devices that are located at the edge of a network, such as smartphones, tablets, laptops, sensors, cameras, or drones.